 Liberate PDFs
Liberate PDFs
Created Tuesday 03 March 2015
This tutorial was written as a help material for Liberate PDF event. I have tried to make the tutorial as generic as possible so it can be used as a base material for any PDF scpraing process. Some of the examples used here are real use cases.
Simple Tools
PDF Tables
- PDF Tables
- Webservice, nothing to install
- Free as in free beer
- For extracting tables from PDFs

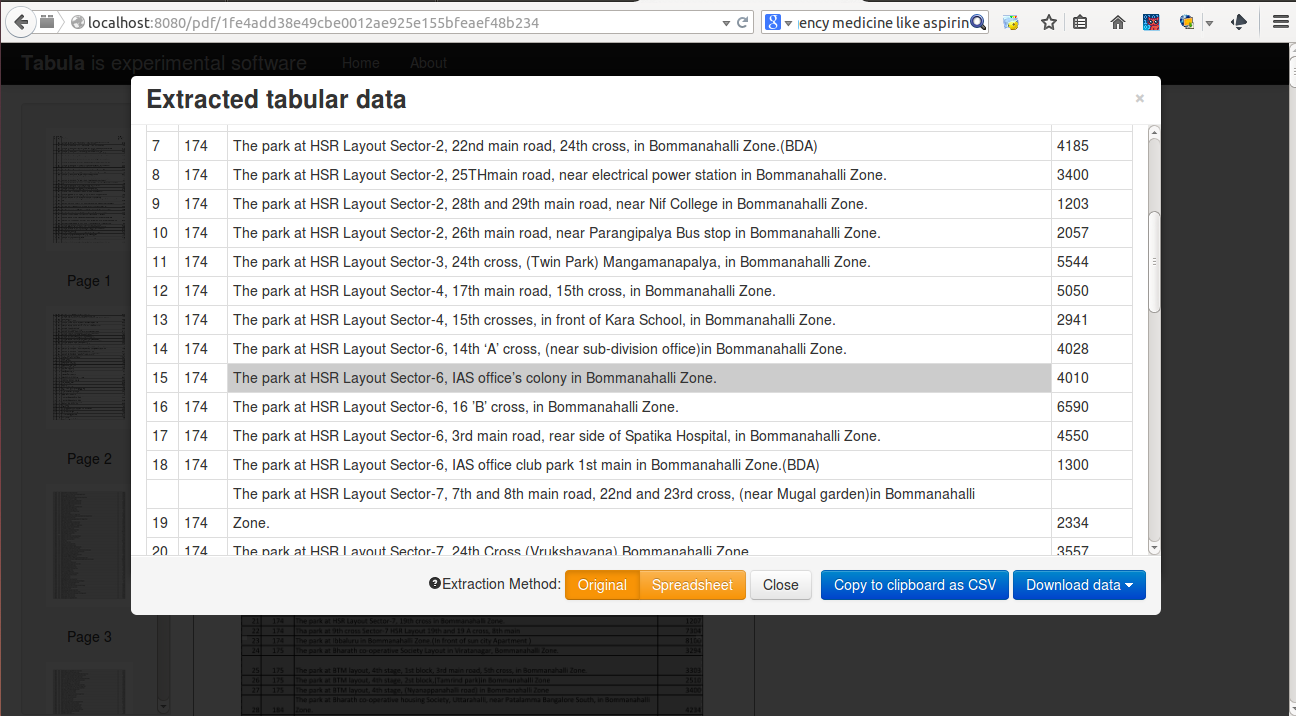
Tabula
- Tabula
- Runs locally as a webservice. Can be installed for the organization or an institution
- FOSS
- Scrapes most pdfs (except the ones which have embedded images)
Smart PDF
- http://smallpdf.com/pdf-to-jpg
- All kind of interconversion
Dig deeper
iText
- iText
- Libraries available for Java and CSharp
- Comercial and AGPL Licensing
- FreeBook available
PDFMiner
- PDFMiner
- Python library
- Can be used to convert PDF to HTML
- Can be used to obtain the exact location of text in a page, as well as other information such as fonts or lines
- FOSS, on GitHub
- Command line tool and can also be used as a python library
- Tutorial
pdftables
- pdftables
- Python library
- Can be used to extract tables
- FOSS
- Command line tool and can also be used as a python library
Apache PDFBox
- Apache PDFBox
- Java Library
- Can extract text from PDF
- Can convert PDFs to images
- Can work with Unicode
- FOSS
PDFTOHTML
- pdftohtml
- pdftohtml is a utility which converts PDF files into HTML and XML formats.
- FOSS
- Best for text pdf conversion
- Primarly command line
pypdfocr
- pypdfocr
- http://virantha.github.io/pypdfocr/html/
- Converts a scanned PDF into an OCR'ed pdf using Tesseract-OCR and Ghostscript
- FOSS
- Take a scanned PDF file and run OCR on it (using the Tesseract OCR software from Google), generating a searchable PDF
- Command line
OCR - tesseract-ocr
- Simple and open source
- Supports Kannada
- Download the intial language files
- Train it for the improvement
- https://code.google.com/p/tesseract-ocr/wiki/ReadMe
- https://code.google.com/p/tesseract-ocr/downloads/list
- https://code.google.com/p/tesseract-ocr/wiki/TrainingTesseract3