Embedding models for Kannada
Embedding models transform words, sentences, documents, or digital items into vectors of numbers (usually floats) so that machines can understand and compare them semantically1. A good embedding model has enough information to capture the meaning and relationships in dense vector form.
I have been using them to replace simple FTS, to implement sophisticated RAG applications, etc. Most embedding models are English-only; however, some multilingual models are available, but their quality varies significantly. So, I conducted a small exercise to determine the optimal embedding model for Kannada. You can find the marimo notebook here. 2 This is inspired by Anand’s Embedding similarity threshold post.
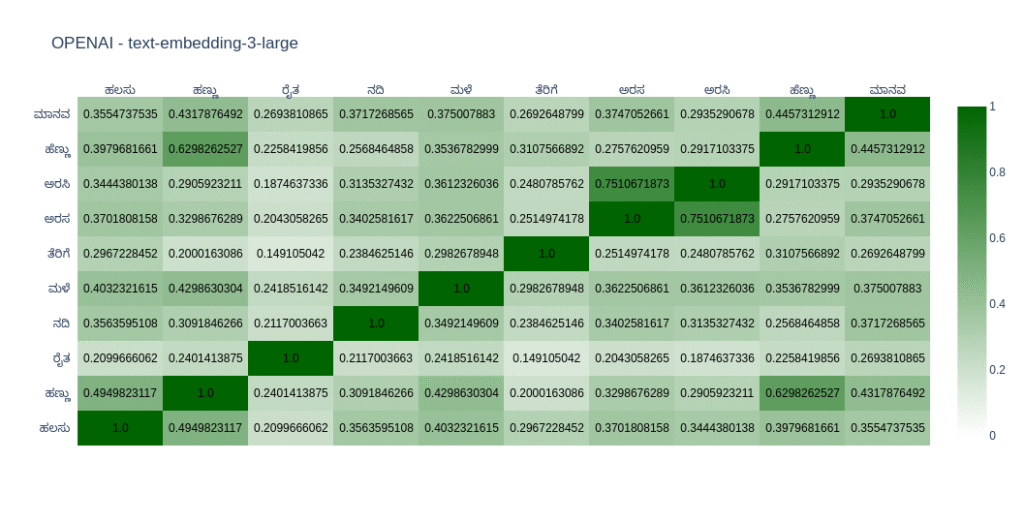
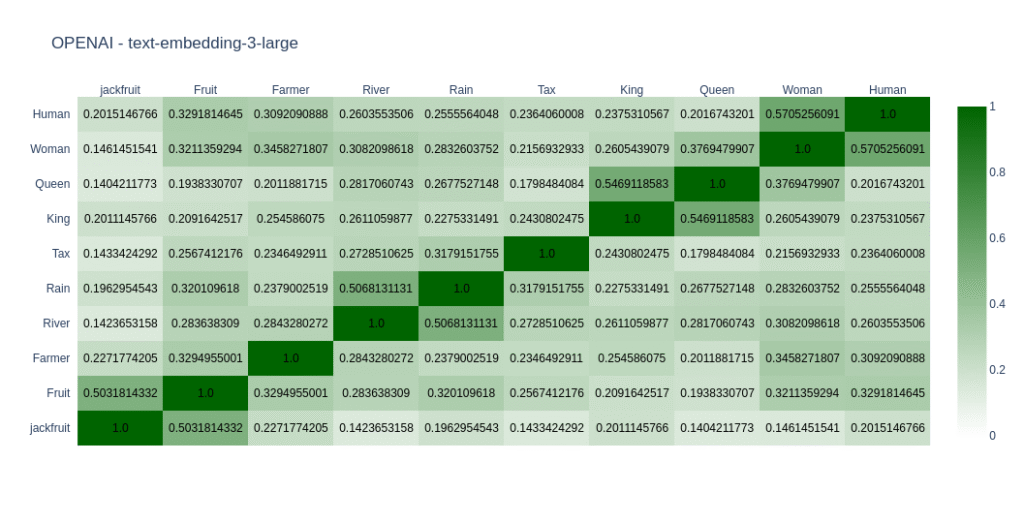
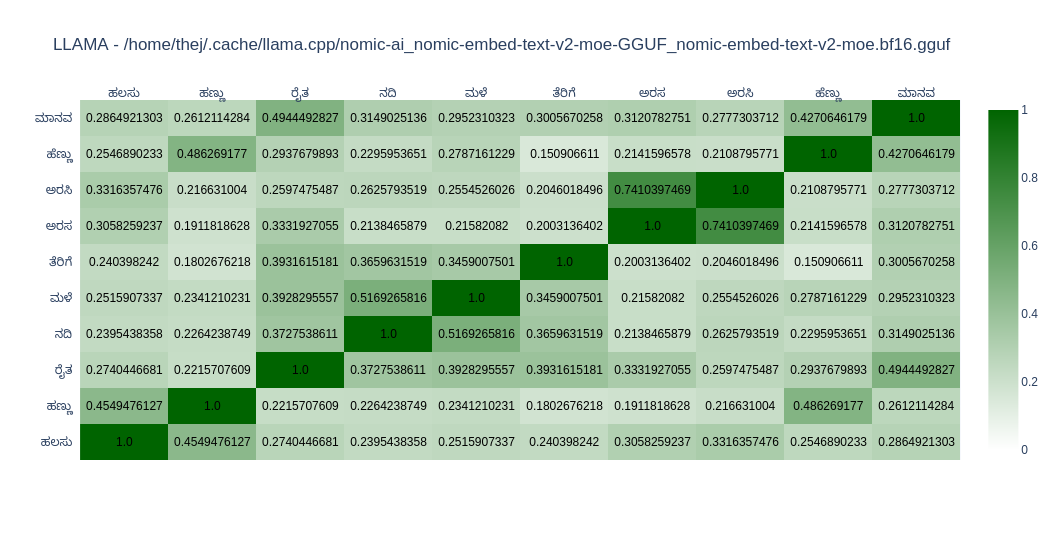
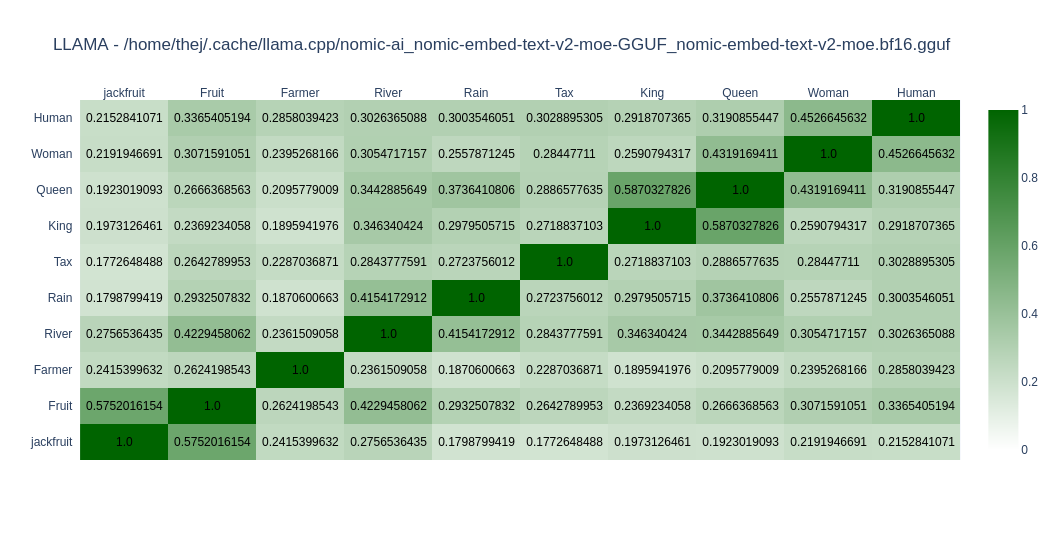
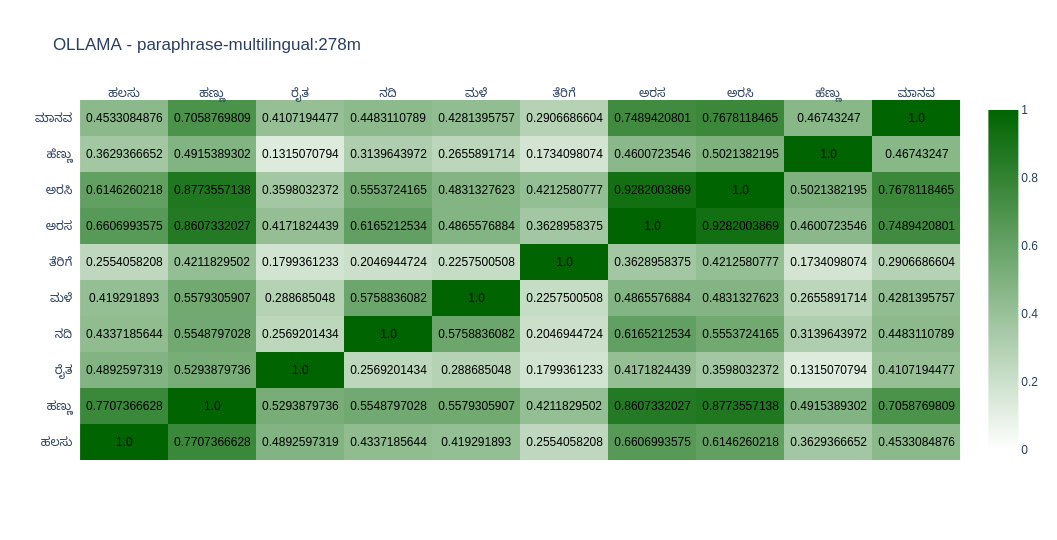
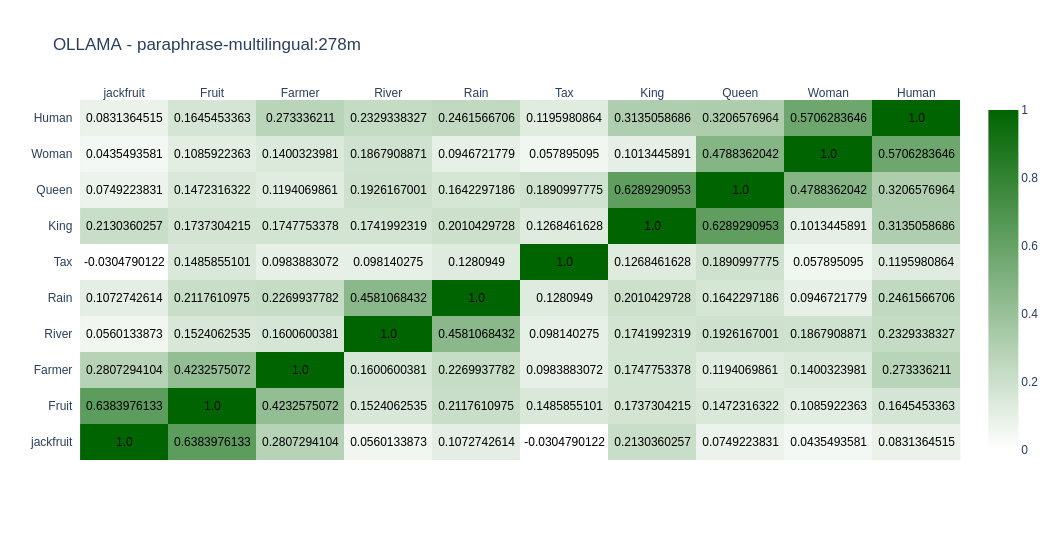
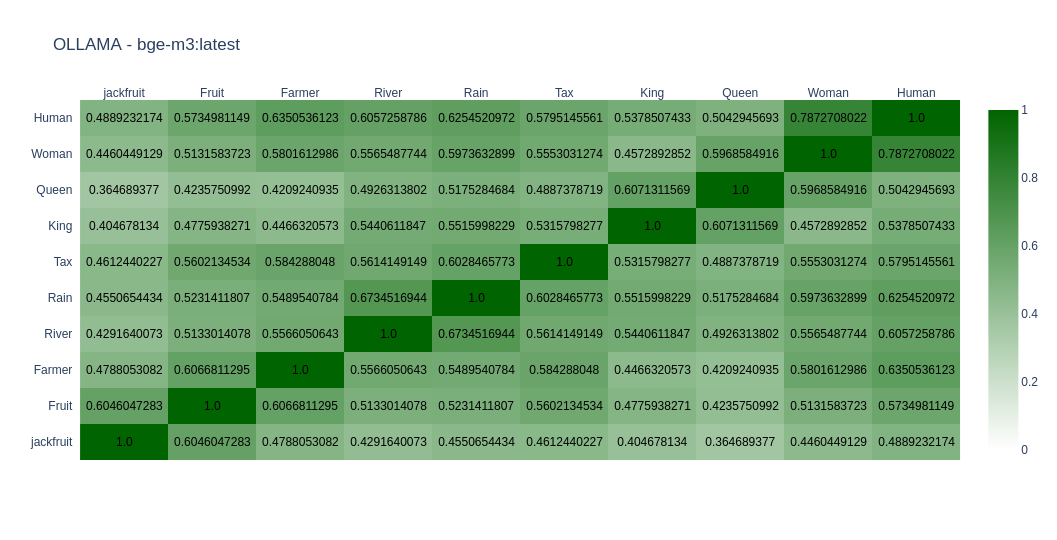
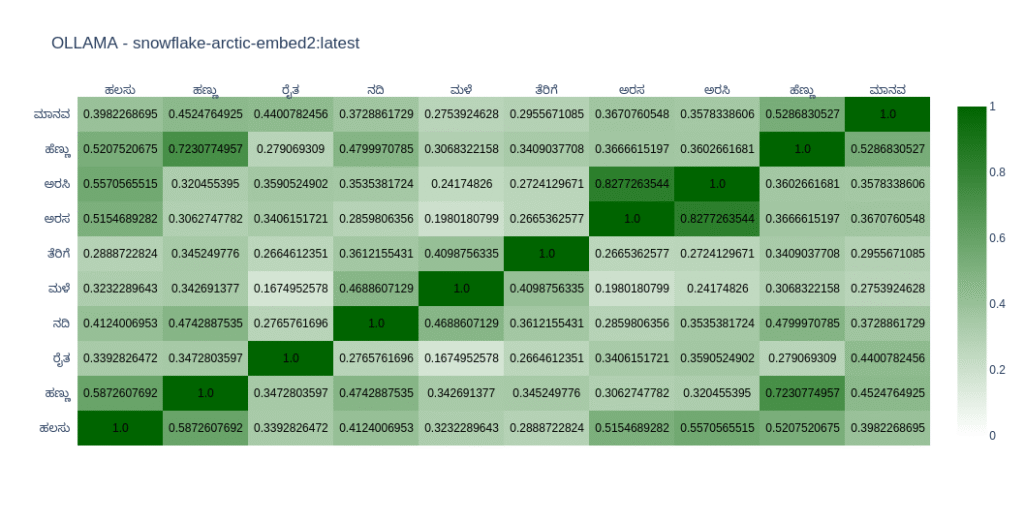
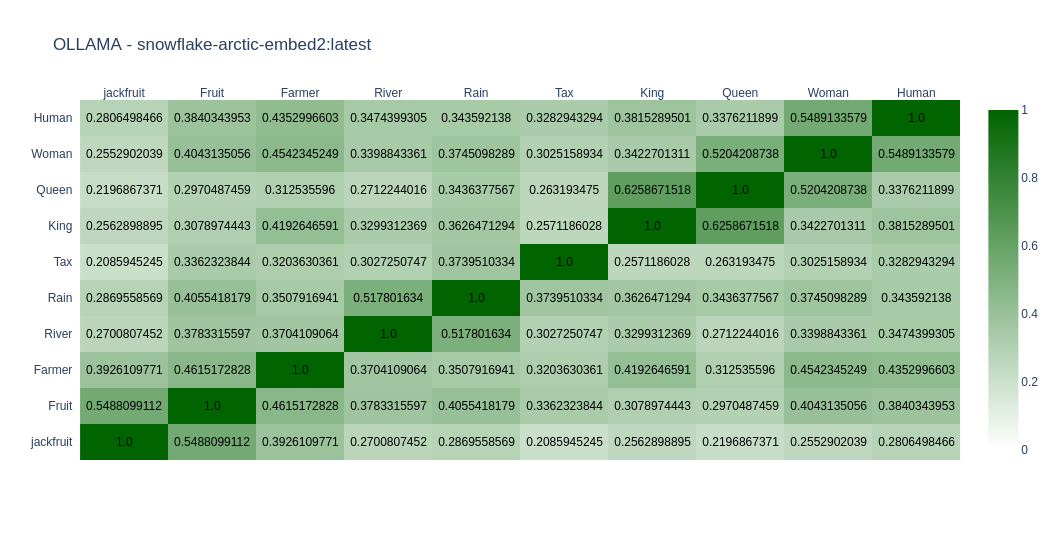
As expected, most models do well in English compared to Kannada. You can come to your conclusions by looking at the graph. In Open Weight models, I found nomic-embed-text-v2-moe and snowflake-arctic-embed2 close to my taste as far as Kannada is concerned. In closed models OpenAIs text-embedding-3-large does well. But its the only closed model I tried.
I am yet to try the closed models by Voyage, Cohere, and Open Weight model – intfloat/multilingual-e5-large-instruct. I have added them to the list. I will try them in the next post.
Table of Contents
Open Weight Models
nomic-embed-text-v2-moe
nomic-embed-text-v2-moe is a state-of-the-art multilingual Mixture-of-Experts Embedding Model text embedding model that excels in multilingual retrieval.
paraphrase-multilingual
paraphrase-multilingual is a sentence-transformers model: It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for tasks like clustering or semantic search.
bge-m3
BGE-M3 is based on the XLM-RoBERTa and is known for its versatility in Multi-Functionality, Multi-Linguality, and Multi-Granularity.

snowflake-arctic-embed2
Arctic Embed 2.0 by Snowflake is their latest frontier embedding model, which has multilingual capabilities.
OpenAI Model
text-embedding-3-large