Connecting KoboToolbox to CouchDB for Real Time Data
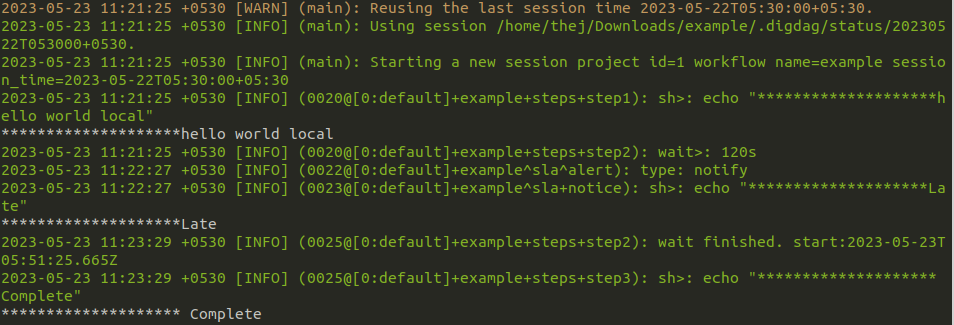
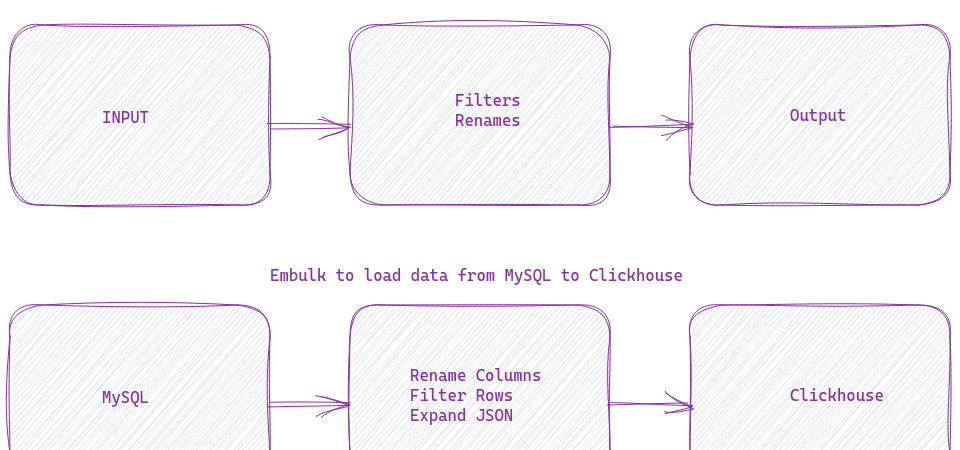
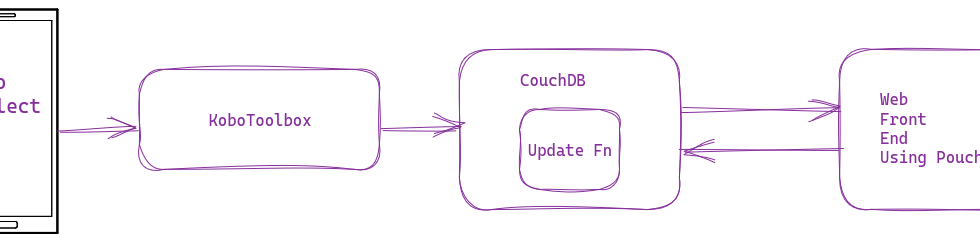
I have recommended KoboToolbox (and KoboCollect) for nonprofits, and we also use it at DataMeet to collect all kinds of data, including IDVC. For IDVC, I pull the data from KoboToolbox, do some massaging, and then upload it to CouchDB. It works very well. But what if I want to make this whole process real-time?