Embulk for extracting and loading data
I recently had a use case where I had to extract data from one source and load it into another. I was looking for a simple but robust tool that could do this. Since I have been using Digdag for years without any issues, I looked at Embulk from the same team.
Embulk is a bulk data loader. It helps transfer data between different types of databases, storages, file formats, cloud services, etc.
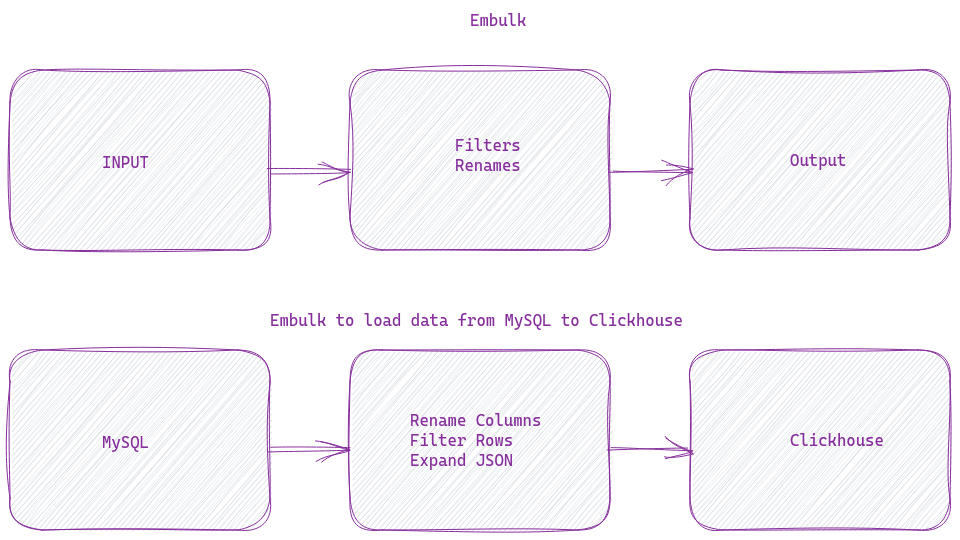
A simple Embulk setup will look like the image shown above. It has inputs ( data source ), filters ( some action on data), and out outputs ( destinations). Various inputs, outputs, and filters are supported using the plugin architecture. Embulk in itself brings them together and runs it. Embulk provides
- Combination of input and output from varieties of plugins
- Plugins released in Maven and Ruby gem repositories
- Automated guess of input file formats
- Parallel execution
- Transaction support (run everything or fail)
- Support for Idempotency (re-runs)
So it was writing a simple YAML configuration file to do this. But later, I configured this Embulk to run on Digdag as a task to make it part of a DAG. I also went further and wrote a python task that dynamically creates Embulk YAML files using Digdag secrets and destroys the YAML file once the workflow is complete. I could have used liquid templates, but I found this more useful. I will write in detail about that later.
It’s like a Unix tool. It’s simple, robust, and works well with other tools. So if you are looking for a simple tool that can extract and load data, I think Embulk works very well. Give it a try, and let me know.











3 Responses
[…] https://thejeshgn.com/2022/12/15/embulk-for-extracting-and-loading-data/ […]
[…] use Embulk with Digdag if the job is about loading data or converting between different types of data or […]
[…] very human-readable. But there are cases where I want the YAML files to generate dynamically. Embulk does support an experimental feature that involves liquid templates. But my team is well versed in […]