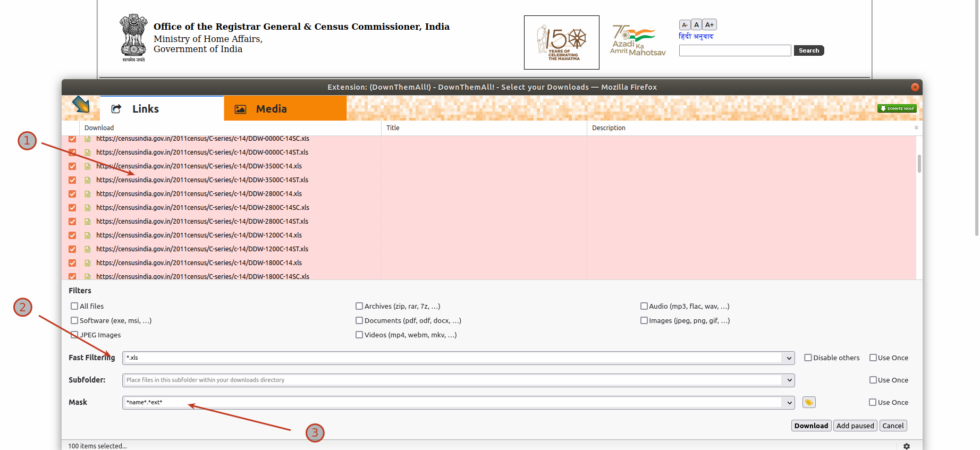
How to Download Them All
One of the primary jobs as a Data Archivist at DataMeet is to download and archive the data from the internet. Mostly from government websites. I usually use python scripts to download, scrape and clean the data. But sometimes, I just need to download many files and store them. I could still use python, but its an overkill. So here are some of the methods that I use.