Speech Note: App for Offline Speech to Text, TTS, and Translation
I’ve always dreamed of talking to computers. Cloud tools made it possible, but nothing beats doing it right on your machine. The first one I encountered that ran well locally was Dragon Speak. It worked pretty well but was very expensive and closed.
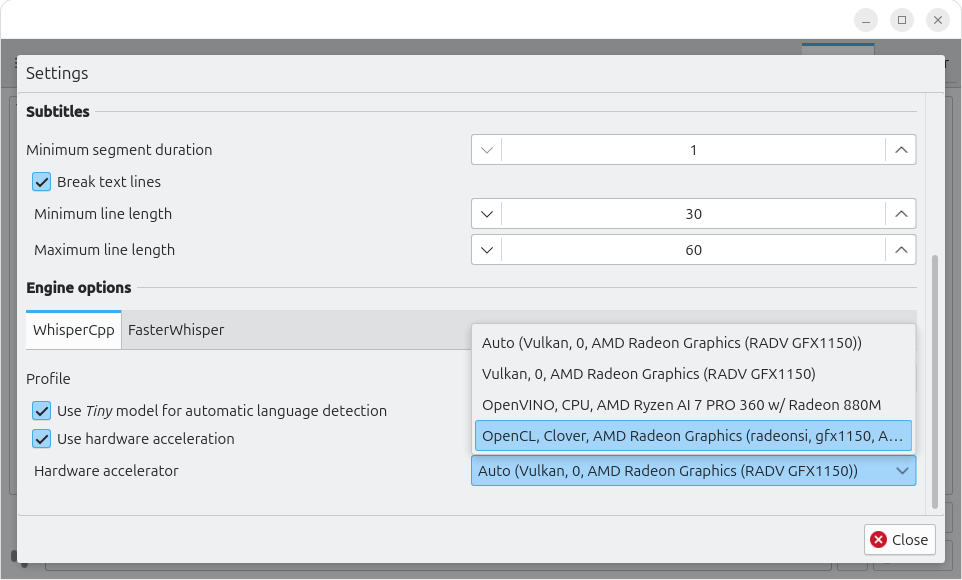
In recent years, few models can run locally and do well. OpenAI Whisper took it to the next level. However, it wouldn’t run on my LC230. Then there were derivatives like Whisper.CPP, which offered tiny models with modest accuracy even on my LC230. That changed drastically with the arrival of a new laptop that can run medium-sized models with reasonably good accuracy.
So now I run Speech Note (dsnote) all the time. Speech Note is a Linux app that can be used for writing, reading, and translating with offline Speech to Text, Text to Speech, and Machine translation models. It supports hundreds of models you can download and run from the app. It’s an all-in-one app that is packaged well.
Speech to Text
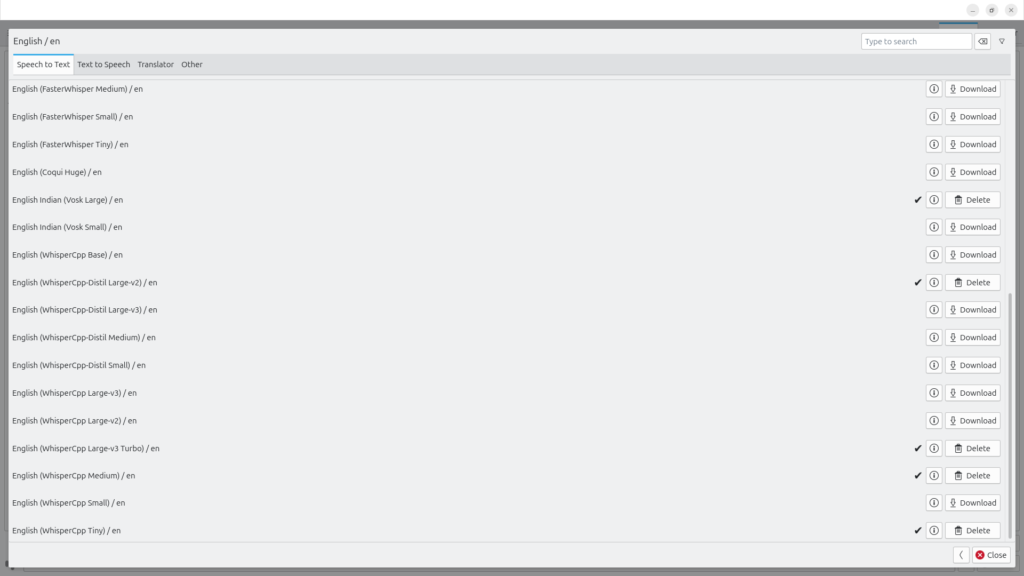
It has many models available (including any of your custom models). Since I run it on a laptop without a dedicated GPU, picking a model always means balancing GPU load, speed, and quality. Here is my table.
| Model | Size | Optimized For | Indian Accent Support | Speed | Accuracy |
|---|---|---|---|---|---|
| FasterWhisper Medium | Medium | Speed + Accuracy | General | Fast | High |
| FasterWhisper Small | Small | Speed | General | Very Fast | Medium |
| FasterWhisper Tiny | Tiny | Speed | General | Fastest | Low |
| Coqui Huge | Huge | Accuracy | Unknown | Slow | High |
| Vosk Large (Indian) | Large | Indian Accent | Yes | Medium | High |
| Vosk Small (Indian) | Small | Indian Accent | Yes | Fast | Medium |
| WhisperCpp Base | Base | General | Limited | Medium | Medium |
| WhisperCpp-Distil Large-v2 | Large | Balanced | Moderate | Fast | High |
| WhisperCpp-Distil Large-v3 | Large | Balanced | Moderate | Fast | High |
| WhisperCpp-Distil Medium | Medium | Speed | Moderate | Fast | Medium |
| WhisperCpp-Distil Small | Small | Speed | Moderate | Very Fast | Low |
| WhisperCpp Large-v3 | Large | Accuracy | Moderate | Slow | High |
| WhisperCpp Large-v2 | Large | Accuracy | Moderate | Slow | High |
| WhisperCpp Large-v3 Turbo | Large | High Accuracy | Moderate | Medium | Very High |
| WhisperCpp Medium | Medium | Balanced | Moderate | Fast | Medium |
| WhisperCpp Small | Small | Speed | Moderate | Very Fast | Low |
| WhisperCpp Tiny | Tiny | Speed | Moderate | Fastest | Very Low |
Of course, you can download multiple models and choose a specific model at any point.

Text to Speech
Same with TTS, here I have gone with Piper librettr_s models. I like Kathleen’s voice. This is my default. It’s fast, clear and quite pleasant to listen to.
Translation
My translations are mostly from German to English. So many OSM related articles are in German.
Actions
Speech Note (dsnote) also supports calling actions through the command line. So, you configure your OS-level customization, automations and shortcuts. For example, I have Ctrl+Alt+L to start listening.
flatpak run net.mkiol.SpeechNote --action start-listening
Supported actions
Invokes an action
Supported actions (@action_name) are:
start-listening
start-listening-translate
start-listening-active-window
start-listening-translate-active-window
start-listening-clipboard
start-listening-translate-clipboard
stop-listening
start-reading
start-reading-clipboard
start-reading-text *
pause-resume-reading
cancel
switch-to-next-stt-model
switch-to-prev-stt-model
switch-to-next-tts-model
switch-to-prev-tts-model
set-stt-model *
set-tts-model *
* Optional 'argument' is used to pass model-id or
text to read. To pass both, set 'argument' to
"{model-id}text to read".
Settings
Need help
I’m still looking for good FOSS options for Kannada TTS, Indian English STT voices, and English↔Kannada translation models. Send your recommendations my way.











Thanks for this info. I’ve been meaning to get back into Natural Language Processing stuff. My earlier days was dealing with DeepSpeech and Tesseract, and also Mycroft. It’s gonna take a little while for me to follow up all the threads to see which projects are still viable, which have viable forks, and which have largely been replaced. The requirement for local processing for any of these machine learning / translation components is paramount. The energy consumed by AI is unconscionable, not to mention the squandering of trillions.
I think you will like piper for TTS. It’s light and used by other projects that I use like HomeAssistant. For STT, I find FasterWhisper Small good enough.