First Impressions of Sarvam Indic Translate Model
I have been searching for models that perform translations between Kannada and English and vice versa. I learned about the Sarvam Translate model, which seemed very promising. I tried it on their site before downloading the model directly to run locally. Model weights are available under GPL.
Sarvam-Translate is an advanced translation model from Sarvam AI, specifically designed for comprehensive, document-level translation across the 22 official Indian languages, built on Gemma3-4B-IT. It addresses modern translation needs by moving beyond isolated sentences to handle long-context inputs, diverse content types, and various formats. Sarvam-Translate aims to provide high-quality, contextually aware translations for Indian languages, which have traditionally lagged behind high-resource languages in LLM performance.
I have mixed feelings about it. Let’s start with the announcement blog post. It contains lots of details about the model and how it was built. I love reading the details; so good. Also, this is a multi-lingual model that can process 22 scheduled Indian languages. But I am focused on Kannada here.
I am interested in translations of idioms, phrases, prose, poetry, etc. And how they translate into English or vice versa. The example from their blog post is good, but it has a very obvious and staggering error — the title “The Monkey and the Wedge” is translated into ಮಂಗ ಮತ್ತು ಗೂಡು. ಗೂಡು in Kannada means nest. Wedge translates to ಗೂಟ or ಬೆಣೆ.
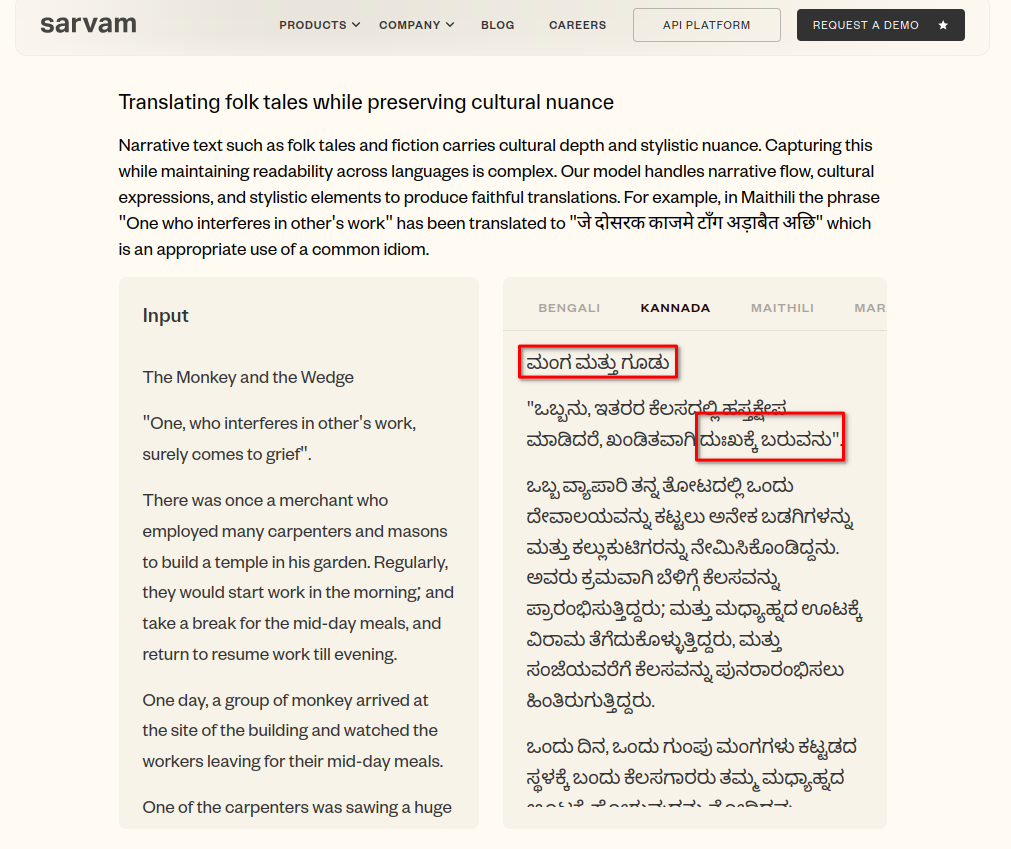
And the phrase comes to grief is translated to ದುಃಖಕ್ಕೆ ಬರುವನು. It’s literally translated. It’s not entirely incorrect, but it’s unusual and odd. In Kannada, we don’t use such a phrase. ಖಂಡಿತವಾಗಿಯೂ ದುಃಖಿತನಾಗುತ್ತಾನೆ is closer to what one would use.
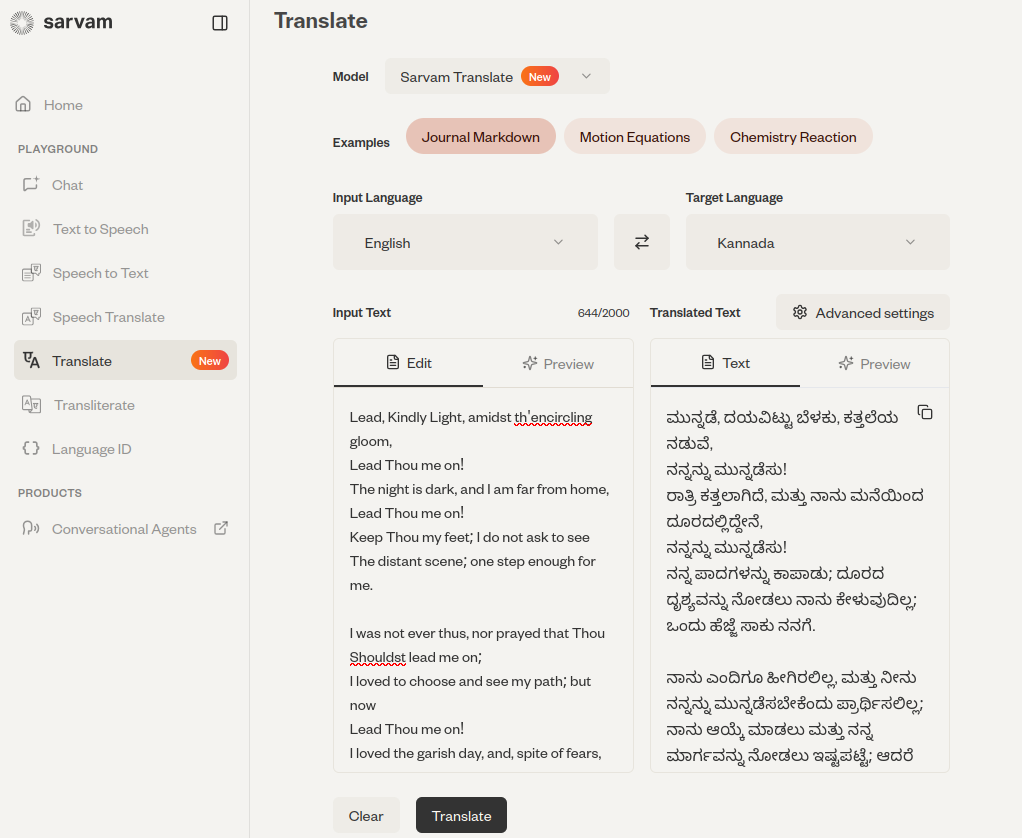
I also, for fun, did a translation of a prayer/poem that Lead, kindly Light. Its below. IRL it’s translated by ಬಿ.ಎಂ.ಶ್ರೀ. The translation by Sarvam Translation is not great, but it is good enough to understand the poem.
Below, I have the translation of Kuvempu’s Wikipedia page from English to Kannada. It’s good. Some minor changes would make it much better. But it’s not good.
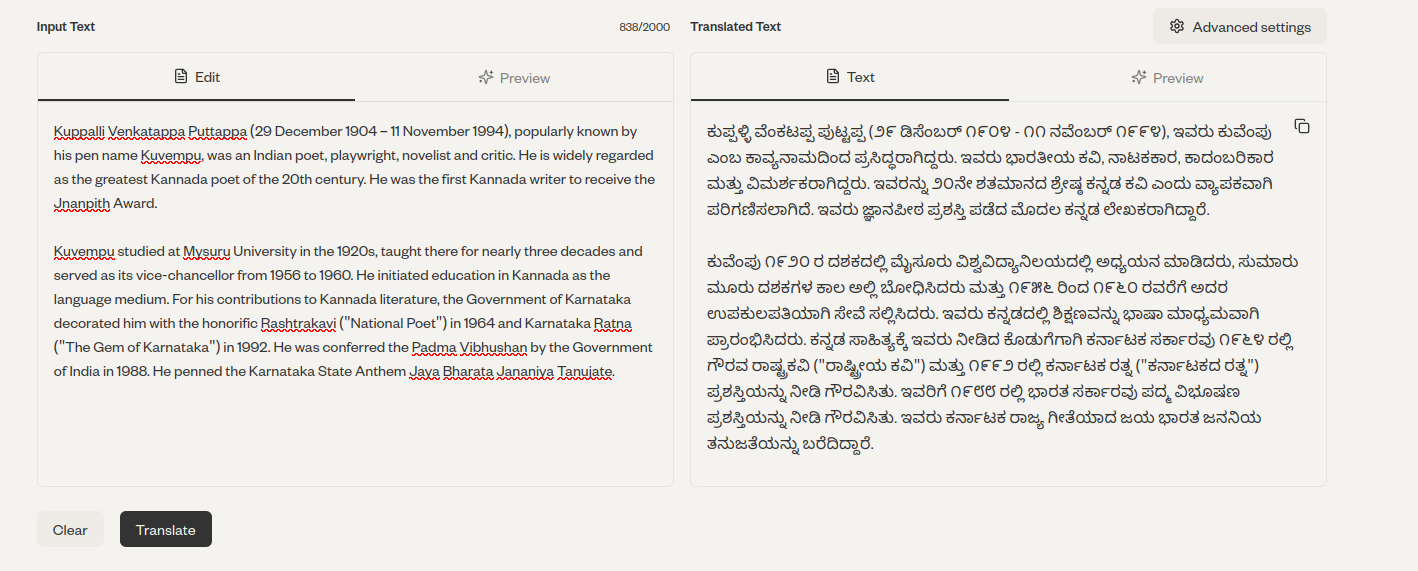
Therefore, for prose and straightforward textual content, such as Wikipedia, I would use it and then perform a quick manual check. For others, such as stories, I would use it, but only as a reference.
Note that it’s not a small model. It’s built by fine-tuning Gemma3-4B-IT. It’s pretty large to run locally, though not impossible. I used their cloud service. This is a very personal evaluation, and in this case, Google Translate performed a bit better. I am not going to post that results of Google Translate here.
Additionally, this is not how they typically test translation models in large-scale evaluations.. However, I think human testing is a good addition to it, as translation is inherently subjective and supposed to be consumed by humans. I also want to create a set of my test cases to evaluate them. So I can do this repeatedly. I will write about it in another post
Final note: You can use it, but with quite a bit of care for now. I am guessing it only improves over time.










Will try the same with Telugu!