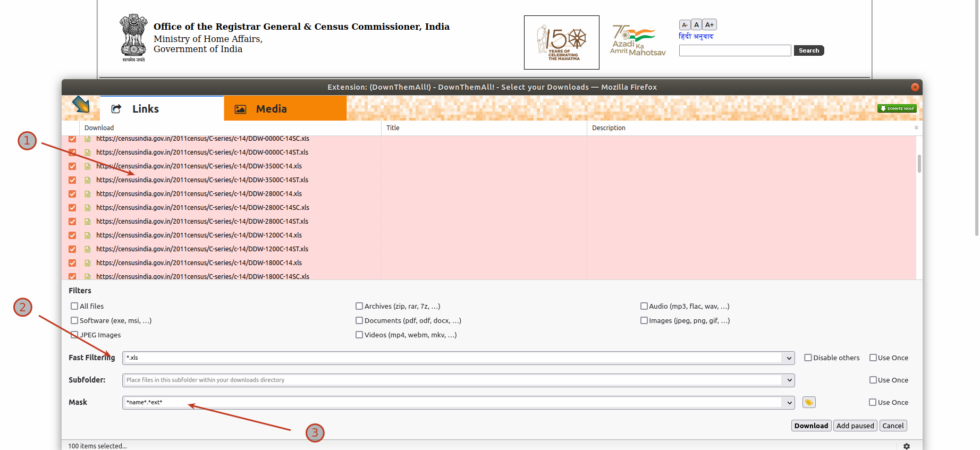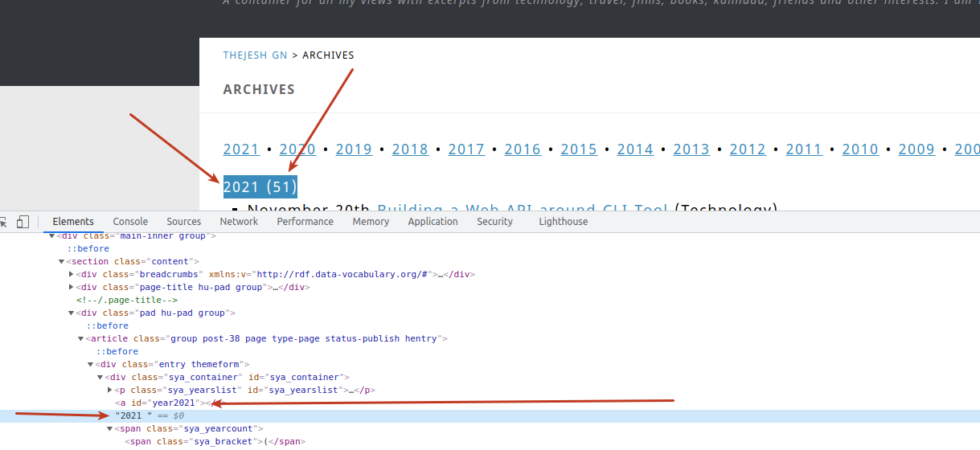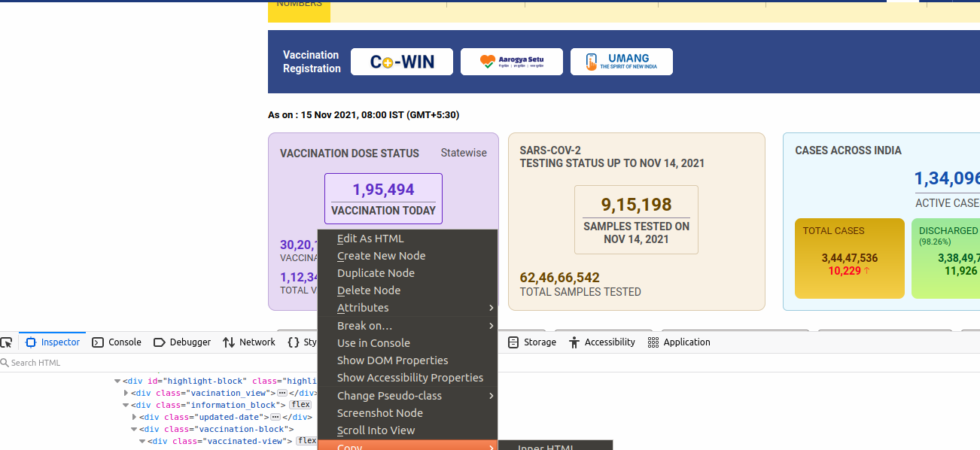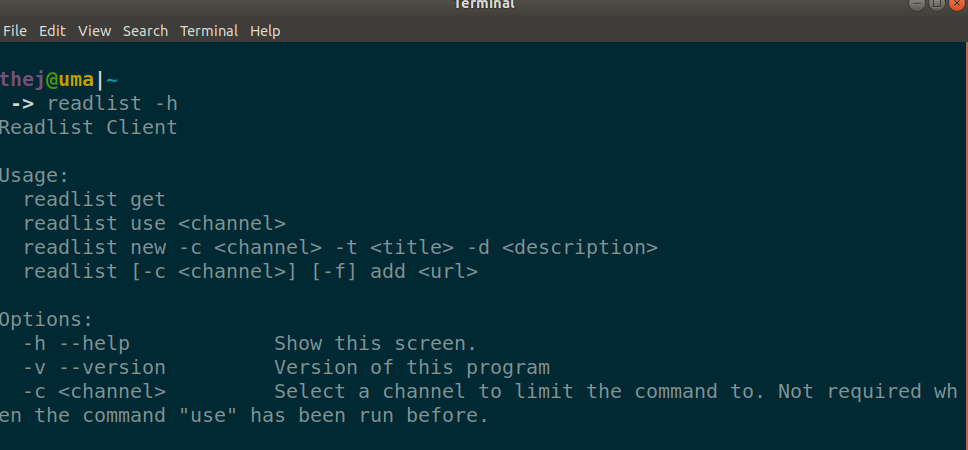
CLI for Readlist
I maintain the readlist in a CouchDB database. Each feed (channel) is a document in that database. I use the file’s name as the primary key i.e “_id”. For example, “sri-lankas-economic-crisis.json” is the key to the Sri Lankan Economic Crisis reading list. It’s a single document. It has many feed items like any JSONFeed. The first few were easy to create and manage. But then I needed something simple to manage this if I was going to be serious about using it.