Scraping National Air Quality Data
we live in Bengaluru/Bangalore. We as family suffer due to air quality. Given this concern, I wanted a data-set to analyze what has happened over the years and what to expect. I also wanted to compare the same with other cities. National Air Quality Index has this data. But it’s available only for major cities and even for cities like Bengaluru they have a very few stations. Bangalore has ten sensors across the city, which is not a lot. Any how this is the only official data-set available. But unfortunately the site doesn’t allow you to download a larger set for personal use. Hence the scraper. Ther scraper has three scripts and a sqilte db cpcbccr/data/db/data.sqlite3. The scripts and some data is available on Github. The code is under GNU GPL v3. Link to this blog post if you like to give credit. I appreciate it, even though its not a requirement :)
1. To start using the script clone the git repo https://github.com/thejeshgn/cpcbccr
git clone https://github.com/thejeshgn/cpcbccr
2. Get the sites for which you want data from https://app.cpcbccr.com/AQI_India/. Like in the screenshot below. Open the data.sqlite3 and add the sites to sites table manually. I use DB Browser for SQLite GUI client. Db is at
cpcbccr/data/db/data.sqlite3
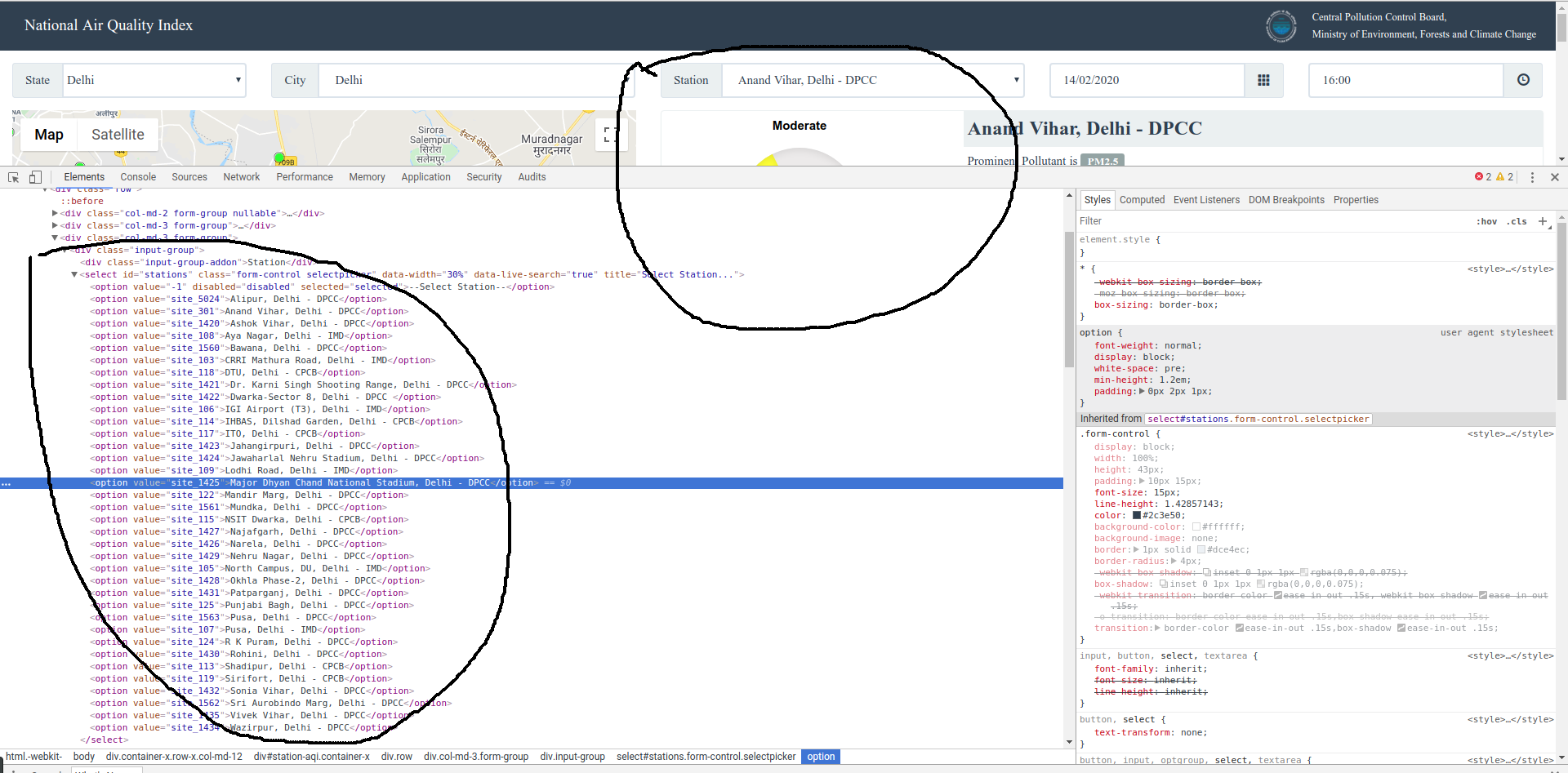
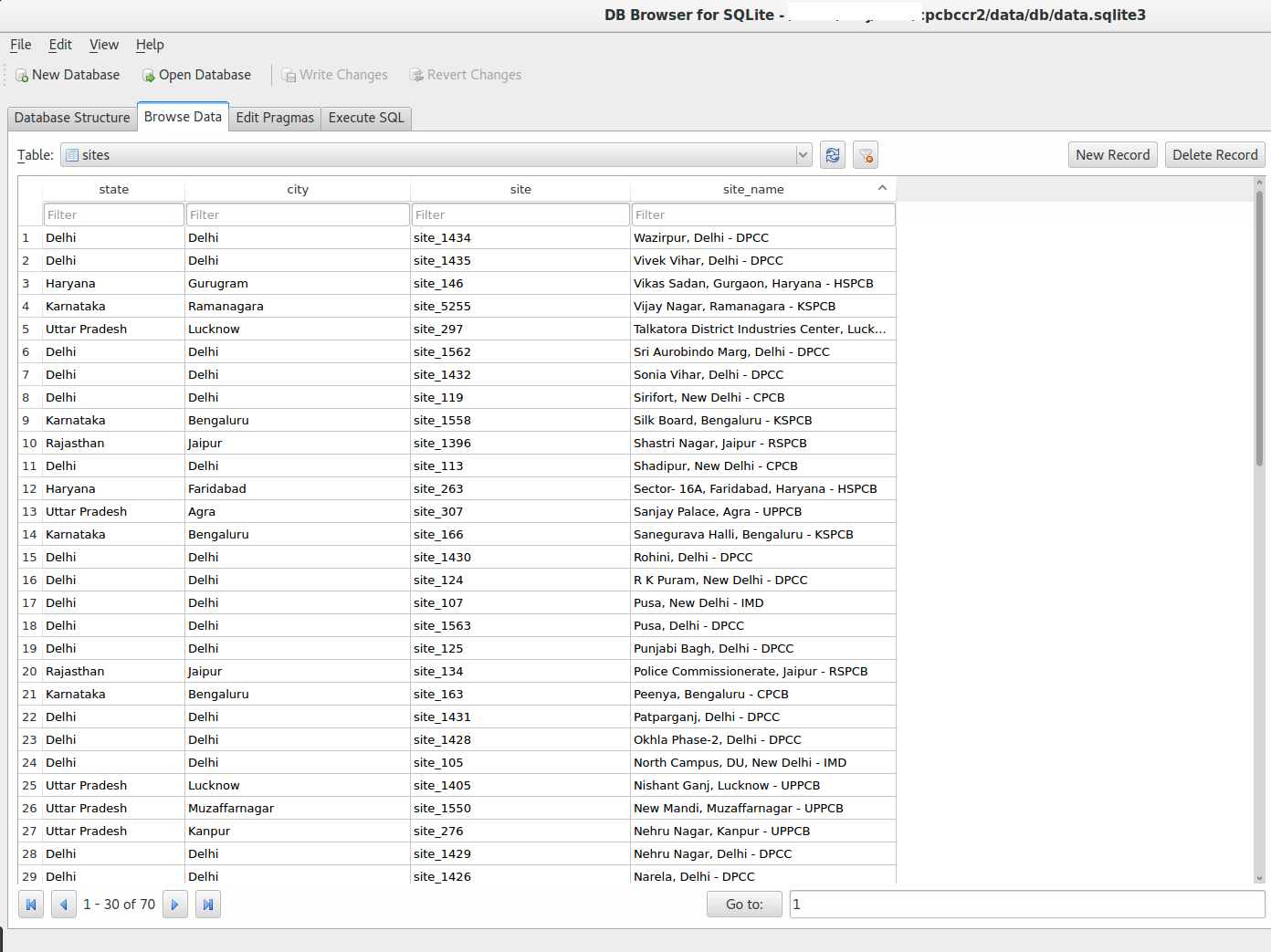
3. Update the fromDate and endDate in setup_pull.py for which data need to be pulled
fromDate = "1-11-2018" #TODO 2: starting date
endDate = "31-10-2019" #TODO 3: ending date, will be next day after that day
4. Install the dependencies and run setup_pull.py – This will setup all the requests that needs to run
pip install dataset requests
python setup_pull.py
5. Run pull.py – This does that requests and pulls the JSON data. You can stop and restart it anytime. Run as slow as possible. Run in batches. As of now it sends one request per five seconds. All the pulled data along with status is stored in request_status_data in data.sqlite3.
python pull.py
6. Run parse.py – It parses the json data and puts into flat table – data
python parse.py
7. Export the data from the table data. Its straight forward.
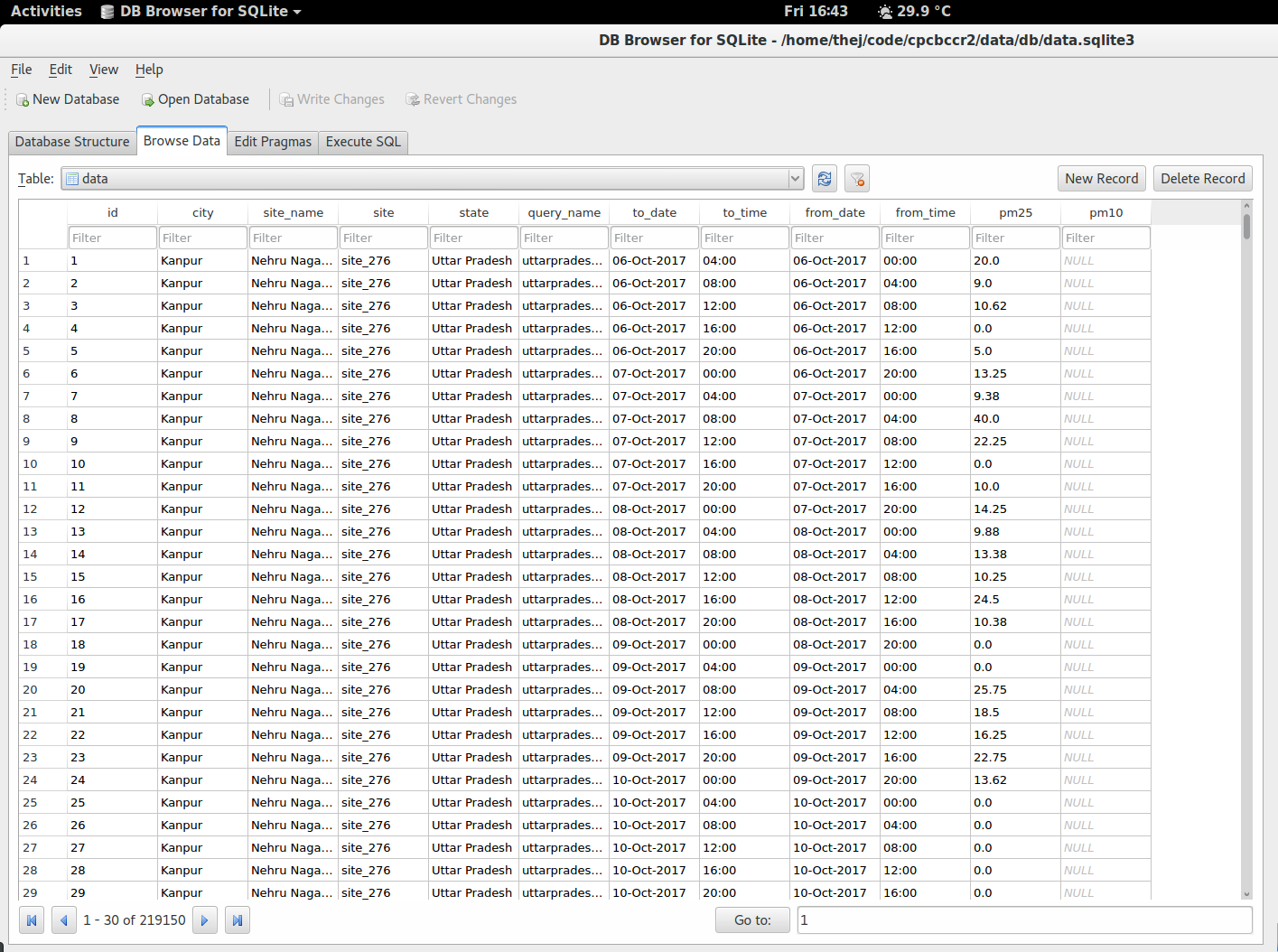
Note. I am pulling only PM10 and PM2.5 as of now. But you can pull other data too. For it in setup_pull.py update the following line
prompt_both='{
"draw": 2,
"columns": [
{
"data": 0,
"name": "",
"searchable": true,
"orderable": false,
"search": {
"value": "",
"regex": false
}
}
],
"order": [],
"start": 10,
"length": 10,
"search": {
"value": "",
"regex": false
},
"filtersToApply": {
"parameter_list": [
{
"id": 0,
"itemName": "PM2.5",
"itemValue": "parameter_193"
},
{
"id": 1,
"itemName": "PM10",
"itemValue": "parameter_215"
}
],
"criteria": "4 Hours",
"reportFormat": "Tabular",
"fromDate": "'+fromDate+'",
"toDate": "'+toDate+'",
"state": "'+state+'",
"city": "'+city+'",
"station": "'+site+'",
"parameter": [
"parameter_193",
"parameter_215"
],
"parameterNames": [
"PM2.5",
"PM10"
]
},
"pagination": 1
}'
You can refer the requests the browser send on this page to form this or similar query.
I have used this code for more than an year now. It seems to work well. Let me know what do you think. In near time I will make the scripts Digdag tasks so it can be scheduled easily.
Question 1: How to get parameter codes?
I received this query by email. I thought its relevant and hence adding it here.
My name is [Retracted] and I am trying to analyse air pollution trends in the country. I came across your GitHub repo and your lucid post to bulk download the data.
First of all, thank you so much for a crucial open-source contribution! It really saves us from a lot of manual work.
In your post, you mention that data for other sensors too can be downloaded and the following line should be updated in the setup_pull.py script:
prompt_both='{“draw”:2,”columns”:[{“data”:0,”name”:””,”searchable”:true,”orderable”:false,”search”:{“value”:””,”regex”:false}}],”order”:[],”start”:10,”length”:10,”search”:{“value”:””,”regex”:false},”filtersToApply”:{“parameter_list”:[{“id”:0,”itemName”:”PM2.5″,”itemValue”:”parameter_193″},{“id”:1,”itemName”:”PM10″,”itemValue”:”parameter_215″}],”criteria”:”4 Hours”,”reportFormat”:”Tabular”,”fromDate”:”‘+fromDate+'”,”toDate”:”‘+toDate+'”,”state”:”‘+state+'”,”city”:”‘+city+'”,”station”:”‘+site+'”,”parameter”:[“parameter_193″,”parameter_215″],”parameterNames”:[“PM2.5″,”PM10″]},”pagination”:1}’
I understood the part where one has to add more sensors as mentioned on the CPCB portal in the exact same format. However, the part that I did not understand is, it appears that each sensor type has a parameter number. For example, PM2.5 and PM2.10 have parameter_193 and parameter_215. I suppose the parameter numbers are unique, where should I find the parameter number for each sensor? or have you already collated a sheet for the same? Apologies in advance if you have already done this and I failed to find.
Would it be possible for you to point me in the right direction? I code, mostly automation and GIS offline development, but always find myself struggling with HTML and team.
Would really appreciate any help you can provide on this.
Step 1: Go to Data Reports Page in Chrome and also open developer tools.
Step 2: Select a state, city and sensor location, select all the Parameters. Click submit. Now it will go to advanced search results page. Now go to dev tools and capture the form details. And decode.
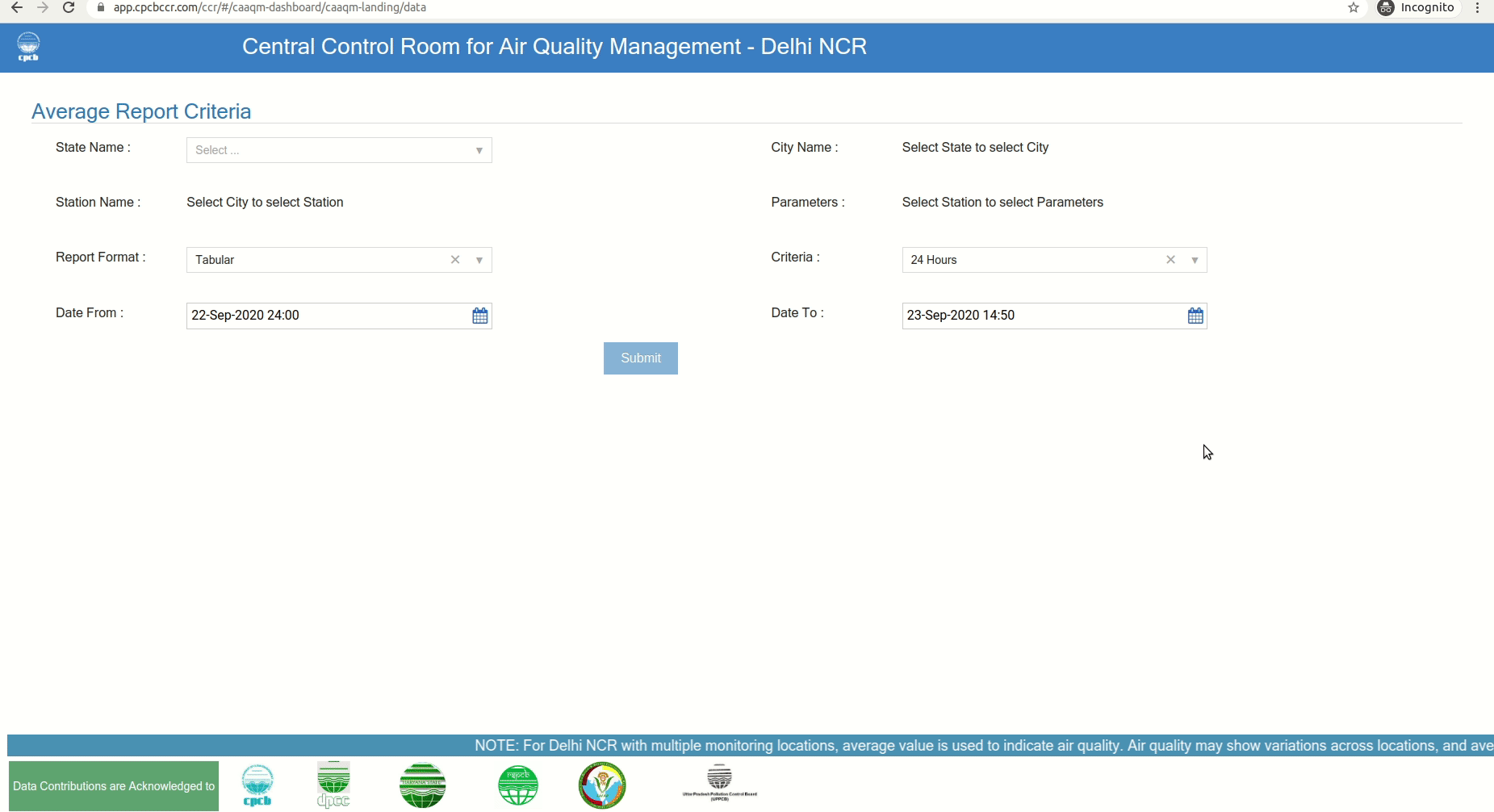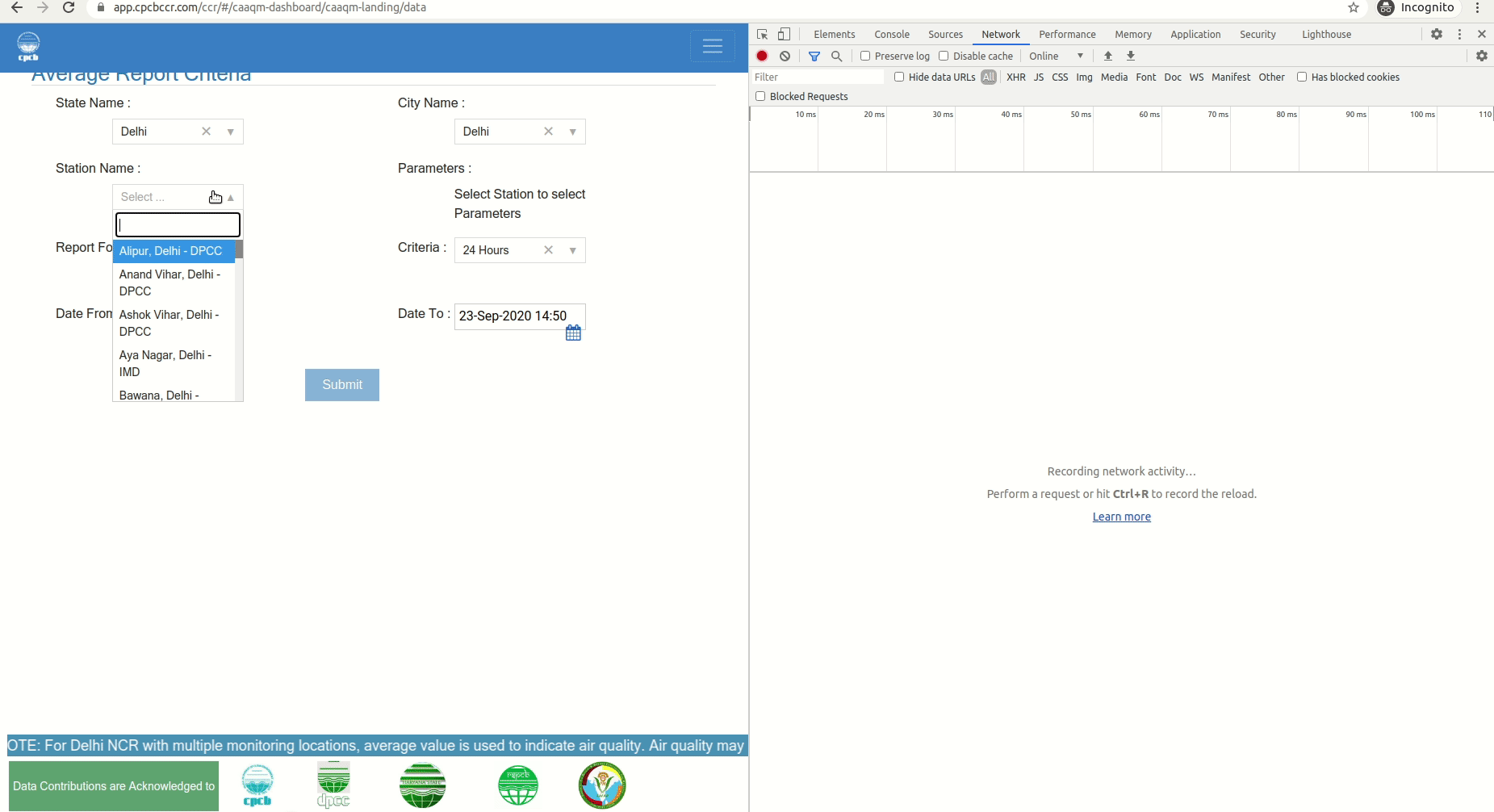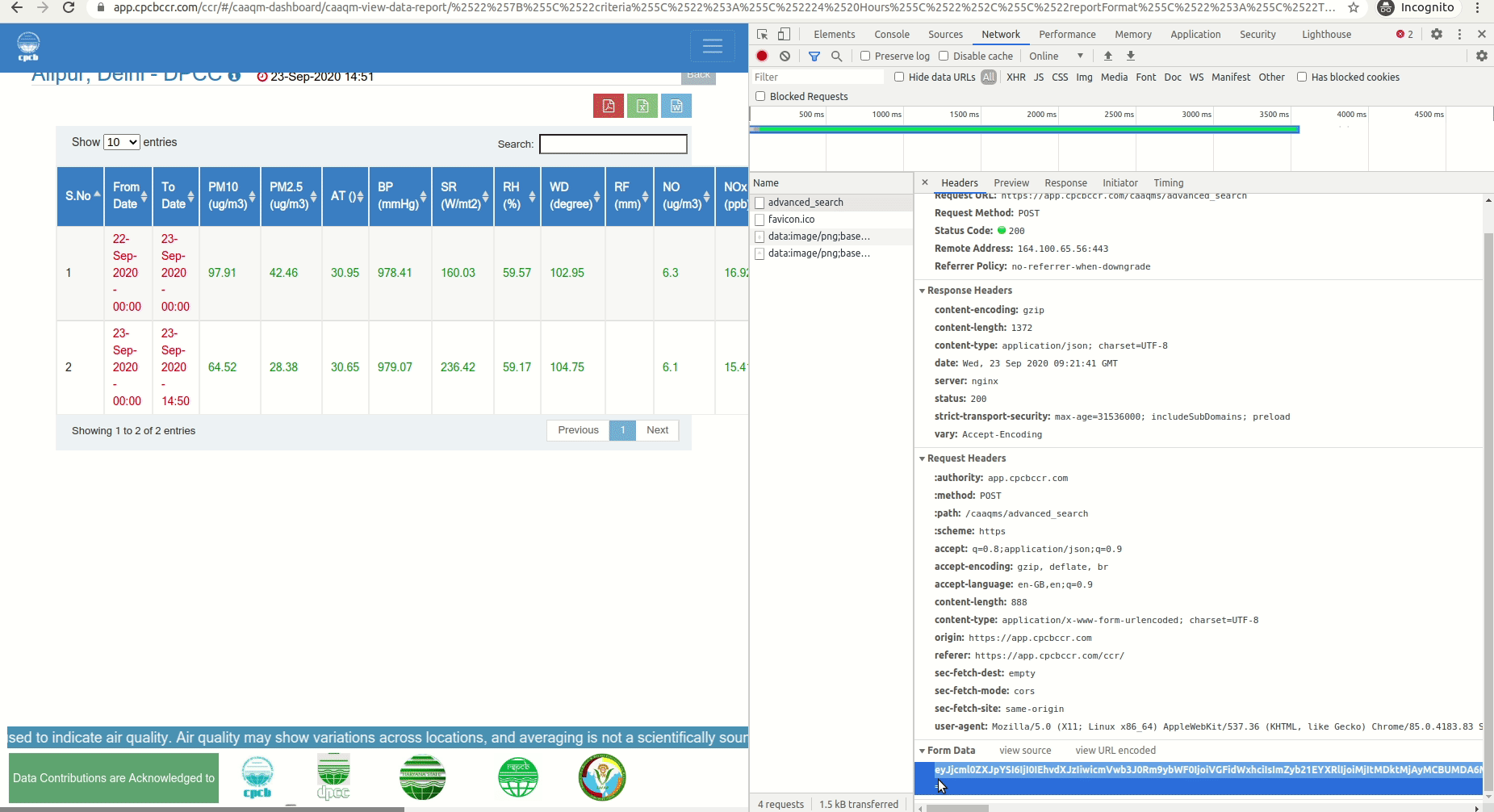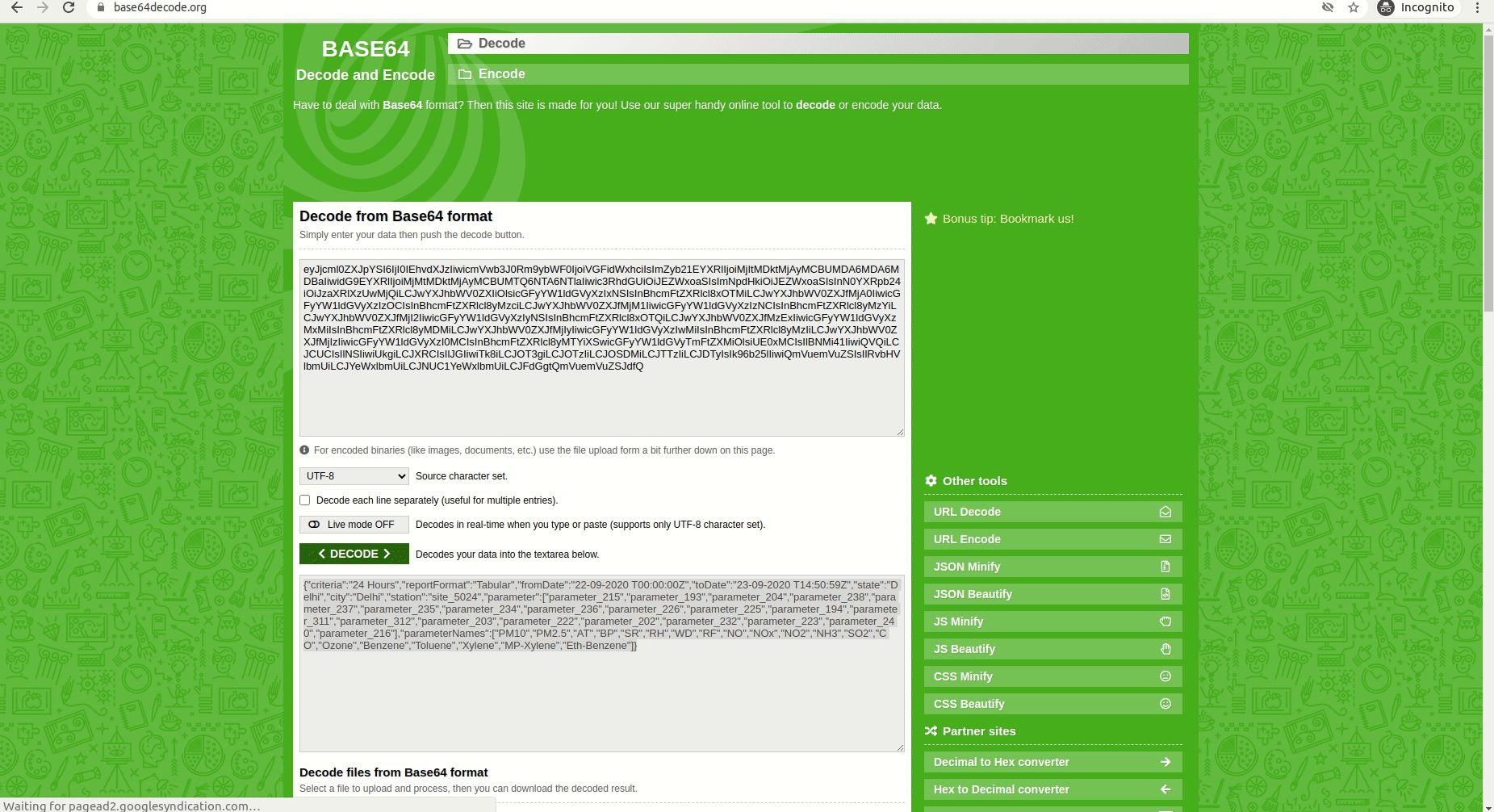
Here is the result of above decoding. It has all the parameter values. You can use it directly.
{
"criteria": "24 Hours",
"reportFormat": "Tabular",
"fromDate": "22-09-2020 T00:00:00Z",
"toDate": "23-09-2020 T14:50:59Z",
"state": "Delhi",
"city": "Delhi",
"station": "site_5024",
"parameter": [
"parameter_215",
"parameter_193",
"parameter_204",
"parameter_238",
"parameter_237",
"parameter_235",
"parameter_234",
"parameter_236",
"parameter_226",
"parameter_225",
"parameter_194",
"parameter_311",
"parameter_312",
"parameter_203",
"parameter_222",
"parameter_202",
"parameter_232",
"parameter_223",
"parameter_240",
"parameter_216"
],
"parameterNames": [
"PM10",
"PM2.5",
"AT",
"BP",
"SR",
"RH",
"WD",
"RF",
"NO",
"NOx",
"NO2",
"NH3",
"SO2",
"CO",
"Ozone",
"Benzene",
"Toluene",
"Xylene",
"MP-Xylene",
"Eth-Benzene"
]
}
Question 2: How to get site id?
Dear Thejesh,
Hope you are well.
Via Email
I am trying to analyse air pollution in Haryana and Punjab too. I need the station name and codes for the same. Would it be possible for you to share those or point me in the right direction?
Thank you in advance!
I got another email asking about the site-id. So I made a screen-cast. If you don’t want to repeat what I have done in the screen-cast. I have the json here for you. and I hope it helps.











Thanks for this post. I found it very easy to download air pollution data!
Got one question: In setup_pull.py, I am trying to modify the query to pull something different – hourly data instead of 4 hours and some additional parameters. In developer tools I couldn’t view the query formed by the browser in the POST request of the page as the parameters are encrypted if my understanding is correct. Is there any other way to view the query? Please suggest
Hey Rajesh,
Just change the ‘criteria’ in prompt_both to “1 hours”.
Yes. Not “1 hour” but “1 hours”
HI how do “itemName”:”PM2.5″,”itemValue”:”parameter_193″ for others parameter like NO2 during post json request?
Answering in public so its useful to everyone.
Step 1: Go to Data Reports Page in Chrome and also open developer tools.
Step 2: Select a state, city and sensor location, select all the Parameters. Click submit. Now it will go to advanced search results page. Now go to dev tools and capture the form details. And decode.
The GiF should help you.
Here it is for all parameters
{ "criteria": "24 Hours", "reportFormat": "Tabular", "fromDate": "22-09-2020 T00:00:00Z", "toDate": "23-09-2020 T14:50:59Z", "state": "Delhi", "city": "Delhi", "station": "site_5024", "parameter": [ "parameter_215", "parameter_193", "parameter_204", "parameter_238", "parameter_237", "parameter_235", "parameter_234", "parameter_236", "parameter_226", "parameter_225", "parameter_194", "parameter_311", "parameter_312", "parameter_203", "parameter_222", "parameter_202", "parameter_232", "parameter_223", "parameter_240", "parameter_216" ], "parameterNames": [ "PM10", "PM2.5", "AT", "BP", "SR", "RH", "WD", "RF", "NO", "NOx", "NO2", "NH3", "SO2", "CO", "Ozone", "Benzene", "Toluene", "Xylene", "MP-Xylene", "Eth-Benzene" ] }While following your post to scrape the CPCB data, I managed to run the setup_pull.py and the pull.py scripts with ease. The pull.py script completed with request code 200, I assume that is a green signal. However, the field json_data[“data”][“tabularData”][“bodyContent”] list is empty.
I read the parse.py script and it appears that it expects some elements in this “bodyContent” list to loop over and populate the datasheet. Could you please let me know if I am doing something wrong? Would be glad to get your inputs.
Facing same issue. Anyone that could work this out ?
hello, sir I am having a problem while running pull.py
File “D:\Personal\cpcbccr-master\code\pull.py”, line 22
encoded_data =row_exists[‘encoded_data’]
^
please help me out with this
Thank you soo much for this post. It really gave me direction on how scaping can be done for air quality data.
On following you post, I am trying to collect data only for Delhi but I am getting below error for setup_pull.py
setup_pull.py”, line 60, in
encoded_data = base64.b64encode(data_to_encode) #Code
File “C:\ProgramData\Anaconda3\lib\base64.py”, line 58, in b64encode
encoded = binascii.b2a_base64(s, newline=False)
TypeError: a bytes-like object is required, not ‘str’
I am running the exact code. Could you please let me know if I am doing something wrong? Would be glad to get your inputs.
Getting the same error ! Please let me know if you were able to solve this !
I am able to resolve above code with
data_to_encode = prompt_all
data_bytes = data_to_encode.encode(“utf-8”)
encoded_data = base64.b64encode(data_bytes)
This works! Thanks, Rishika, for updating!
I will check this week.