DataMeet COVID19 Updates – Vaccination Data
If you are following DataMeet’s COVID19 git repository, you would have observed some changes in how Vaccination data is scaped and added. Until now, we were adding only total at the national level, and now it has first_dose and second_dose details at the national level.
{
"_id": "2021-10-20T09:00:00.00+05:30|vaccinations",
"_rev": "3-367ecd616d5b8af41da5d799fa1c34ad",
"report_time": "2021-10-20T09:00:00.00+05:30",
"total": 991282283,
"source": "mohfw",
"type": "vaccinations",
"first_dose": 701144631,
"second_dose": 290137652
}
I am working on bringing in the state data as well. I have written the PDF scraper. But it’s not there yet, as the PDF format has changed multiple times. But by the end of November, we should have the state-level counts too.
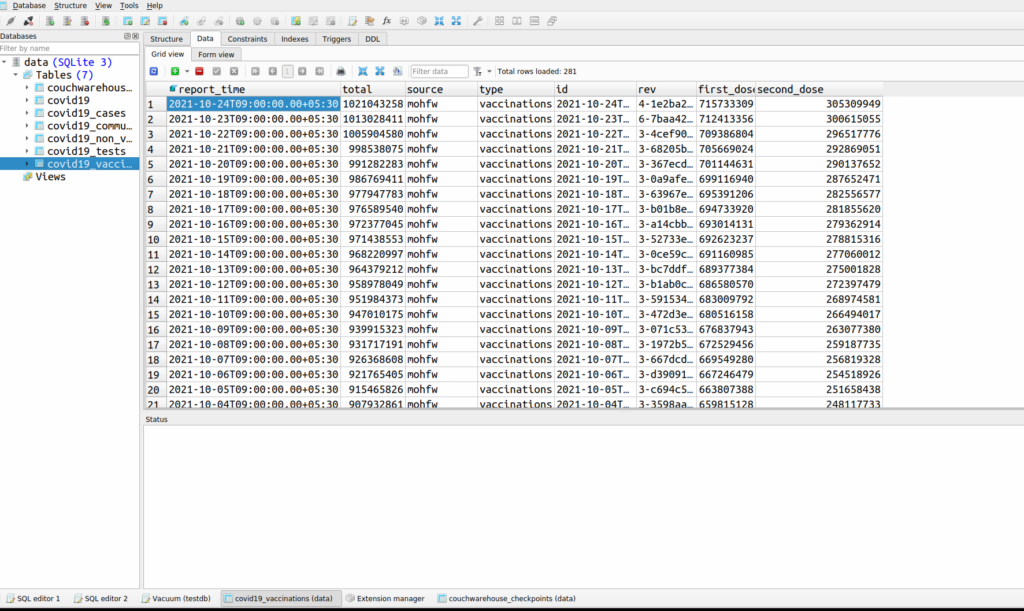
We also have a combined SQLite file now, which has each dataset as a separate table. This is useful for folks who want to use SQL instead of wrangling JSON. One could use tools like SQLite studio or DB browser to analyze the data or export to CSVs. Or you could use this online Datasette based data browser to explore. I am planning to update the SQLite file once a week.
I am yet to update the project page and documentation. Will do. PRs are welcome :)











Hey Thejesh, This is really good initiative.
I believe nocodb[1] can help to make this data more accessible and queryable. NocoDB works like an Airtable over existing databases – you can easily connect your sqlite and share it publicly.
Happy to give a demo sometime. https://calendly.com/nocodb
[1] : https://github.com/nocodb/nocodb