Extract Data from HTML/XML/JSON using Xidel
As you would know, I scrape a lot of web pages as a Data Archivist at DataMeet. I usually use BS4 for this, and it’s beautiful, simple, and works. But often don’t want to write a python script to do that, and I need a simple tool to get data out of HTML.
I want to curl or wget the HTML and pipe to a tool to get the data I want. Xidel is what I use then. Xidel is an old (since 2012) CLI tool that helps you extract data from HTML, XML, or JSON documents. Xidel goes one more step; you don’t even need to do a curl or wget. Xidel does that also for you.
This quick one-paragraph feature list explains what it can do. Visit the tutorial page to learn more.
- Extract expressions:
- CSS 3 Selectors: to extract simple elements
- XPath 3.0: to extract values and calculate things with them
- XQuery 3.0: to create new documents from the extracted values
- JSONiq: to work with JSON apis
- Templates: to extract several expressions in an easy way using a annotated version of the page for pattern-matching
- XPath 2.0/XQuery 1.0: compatibility mode for the old XPath/XQuery version
- Following:
- HTTP Codes: Redirections like 30x are automatically followed, while keeping things like cookies
- Links: It can follow all links on a page as well as some extracted values
- Forms: It can fill in arbitrary data and submit the form
- Output formats:
- Adhoc: just prints the data in a human readable format
- XML: encodes the data as XML
- HTML: encodes the data as HTML
- JSON: encodes the data as JSON
- bash/cmd: exports the data as shell variables
- Connections: HTTP / HTTPS as well as local files or stdin
- Systems: Windows (using wininet), Linux (using synapse+openssl), Mac (synapse)
Here is an example. I want to get the Total Vaccination Count from mygov.in the covid dashboard. This specific data item comes embedded in the HTML, and for Xidel, it’s not a problem.
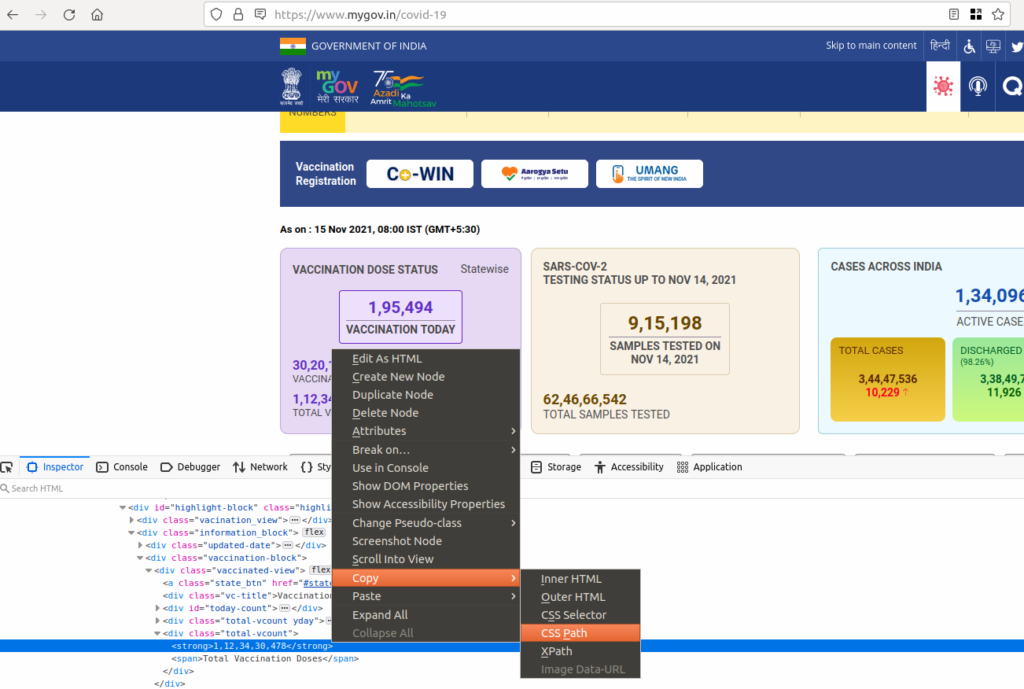
I open the Dev console, select and right-click on HTML node. Then I will copy the CSS selector.
Get the data using CSS selectors.
$xidel https://www.mygov.in/covid-19 --css="div.total-vcount:nth-child(5) > strong:nth-child(1)"
**** Retrieving (GET): https://www.mygov.in/covid-19 ****
**** Processing: https://www.mygov.in/covid-19 ****
1,12,34,30,478
I don’t want any extra logs. Here you go
$xidel https://www.mygov.in/covid-19 --css="div.total-vcount:nth-child(5) > strong:nth-child(1)" --silent
1,12,34,30,478
I want JSON output, no problem.
$xidel https://www.mygov.in/covid-19 --css="div.total-vcount:nth-child(5) > strong:nth-child(1)" --silent --output-format=json-wrapped
[
"1,12,34,30,478"
]
XML output
$xidel https://www.mygov.in/covid-19 --css="div.total-vcount:nth-child(5) > strong:nth-child(1)" --silent --output-format=xml-wrapped
<?xml version="1.0" encoding="UTF-8"?>
<seq>
<e>1,12,34,30,478</e>
</seq>
Even HTML
$xidel https://www.mygov.in/covid-19 --css="div.total-vcount:nth-child(5) > strong:nth-child(1)" --silent --output-format=html
<!DOCTYPE html>
<strong>1,12,34,30,478</strong>
Reading and Parsing JSON is also easy. Here I am using JSONiq notation to extract
$xidel https://www.mygov.in/sites/default/files/covid/covid_state_counts_ver1.json --input-format=json --extract='$json("Death")("15")' --silent
38145
Note: “15” is a string is a key. It’s not an array index
Using dot notation
$xidel https://www.mygov.in/sites/default/files/covid/covid_state_counts_ver1.json --input-format=json --extract='($json).Death.15' --silent
38145
There are lots of features that I am yet to explore. I will write more later.











2 Responses
[…] I will run the xidel and pipe the output to a curl to insert a record into a CouchDB […]
[…] at the year archive count or running a query on the database. But recently, I have started using Xidel, so why not use it? […]