Back to Basics: Build Your Own LLM from Scratch
I did a workshop titled “Back to Basics: Build Your Own LLM from Scratch”, which kind of included some basic theory on how a transformer works, and then building a very small LLM. The idea was to demystify an LLM (or transformer) by understanding what goes on and then building one to deepen our understanding. I had to skip some slides because the planned session was only two hours. Ideally, I want it to be around 4 hours, split into 2 sessions: one for theory and one for lab. Maybe next time, when I plan, I will make it 4 hours so I can do it at a slower pace.
Of course, there are other similar workshops available online, and some of them are linked in the references section. This is just my take on it and what I used for my own understanding.
Suppose you want to try it at your own pace. Try the slides below and then use annotated code to read and run. Slides and code are in a repo too if you prefer that.
#!/usr/bin/env -S uv run --script
# /// script
# requires-python = ">=3.10"
# dependencies = [
# "torch==2.8.0",
# ]
# [tool.uv]
# extra-index-url = ["https://download.pytorch.org/whl/cpu"]
# ///
"""
build_and_test.py (ANNOTATED VERSION FOR WORKSHOP)
A minimal, single-file GPT for "Back to Basics: Build Your Own LLM from Scratch".
═══════════════════════════════════════════════════════════════════════════════
WALKTHROUGH MAP — suggested order
═══════════════════════════════════════════════════════════════════════════════
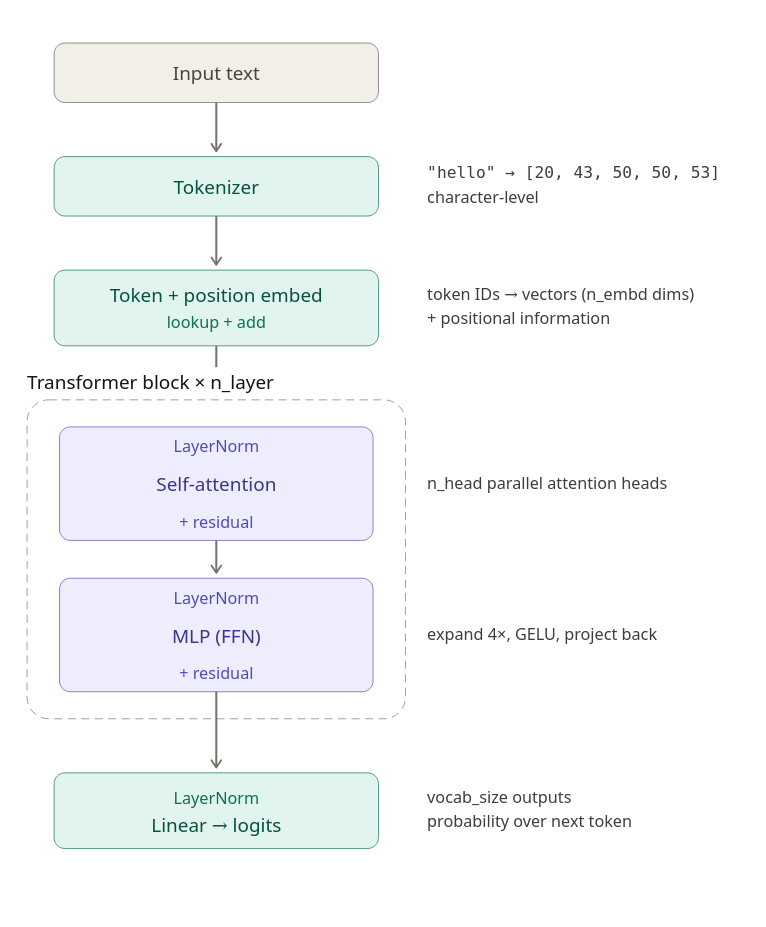
① GPTConfig ← slide "The whole model in 5 numbers"
② CharTokenizer ← slides "Tokens" / "Tokenizer"
③ GPT.__init__/forward ← slide "Recap: what we just built" (the big pipeline)
④ CausalSelfAttention ← slides "Single-head attention" → "Combining heads with Wo"
⑤ FeedForward ← slide "Feed-Forward Network (FFN)"
⑥ TransformerBlock ← slide "One full transformer block"
⑦ get_batch ← (where x/y "next-token" pairs come from)
⑧ train() ← slides "Cross-entropy" → "Training"
⑨ GPT.generate() ← slide "Generation: from logits to text"
Comments marked 💬 are things worth SAYING out loud.
Comments marked ❓ are good questions to ASK the room.
Comments marked ⚠️ are common gotchas / likely audience questions.
Usage:
# Train on a text file (CPU only, by design)
uv run build_and_test.py train --data ../data/shakespeare.txt --max-steps 2000
# Generate from a saved checkpoint
uv run build_and_test.py generate --checkpoint ../checkpoints/run1/final_checkpoint.pt --prompt "To be, or not " --num-new-tokens 200 --temperature 0.8 --top-k 40 --seed 42
"""
import argparse
import csv
import math
import os
import sys
import time
from dataclasses import dataclass, asdict
import torch
import torch.nn as nn
import torch.nn.functional as F
# ═════════════════════════════════════════════════════════════════════════════
# ① CONFIG [Slide: "The whole model in 5 numbers"]
# ═════════════════════════════════════════════════════════════════════════════
# 💬 "These five numbers ARE the model. Everything else is derived from them."
# Point back to this class every time a shape like (B, T, C) appears below:
# B = batch_size, T ≤ block_size, C = n_embd.
@dataclass
class GPTConfig:
# Architecture (the 5 numbers from the slides)
vocab_size: int = 65 # how many unique tokens (set from data, after tokenizer)
n_embd: int = 256 # C: the vector size each token is represented by
n_head: int = 4 # parallel attention heads (d_k = n_embd/n_head = 64)
block_size: int = 256 # T_max: the longest context the model can ever see
n_layer: int = 4 # how many TransformerBlocks we stack
# Training knobs — deliberately NOT in GPTConfig:
# 💬 "These shape the *training run*, not the *model*. A checkpoint doesn't need them."
batch_size = 32 # sequences per training step (the B in (B, T, C))
dropout = 0.1 # ⚠️ on during training, automatically off in eval()
# [Slide: "Training vs. inference" — dropout row]
output_path = "../checkpoints/run1"
# ═════════════════════════════════════════════════════════════════════════════
# ② TOKENIZER [Slides: "Tokens" / "Tokenizer"]
# ═════════════════════════════════════════════════════════════════════════════
# 💬 "A tokenizer has exactly two jobs: encode (text → IDs) and decode (IDs → text).
# We picked character-level — the simplest of the three choices on the slide.
# GPT/LLaMA/Claude use subword BPE; same idea, fancier vocab."
#
# ❓ Ask: "If our vocab is the 65 unique characters in Shakespeare, what happens
# when you prompt with an emoji?" → see encode(): it silently drops unknowns.
class CharTokenizer:
"""Smallest possible tokenizer: one character = one token."""
def __init__(self, vocab: list[str]):
self.vocab = vocab
# stoi = "string to int", itos = "int to string" — two dicts, that's it.
self.stoi = {ch: i for i, ch in enumerate(vocab)}
self.itos = {i: ch for i, ch in enumerate(vocab)}
@classmethod
def from_text(cls, text: str) -> "CharTokenizer":
# 💬 "The vocab is just every unique character that occurs in the data."
# Sorted so the vocab is deterministic across runs
# ⚠️ Without sorted(), set() ordering varies → token IDs change between runs
# → an old checkpoint would decode to garbage. This one line is why we
# can reload checkpoints reliably.
vocab = sorted(list(set(text)))
return cls(vocab)
def encode(self, s: str) -> list[int]:
# text → list of integers. [Slide: "Tokenizer" — encode example]
# `if c in self.stoi`: characters not in the training data are dropped.
return [self.stoi[c] for c in s if c in self.stoi]
def decode(self, ids: list[int]) -> str:
# integers → text. Perfect inverse of encode (for known chars).
return "".join(self.itos[i] for i in ids)
@property
def vocab_size(self) -> int:
# 💬 "This becomes the first of our 5 numbers — vocab_size in GPTConfig."
return len(self.vocab)
# ═════════════════════════════════════════════════════════════════════════════
# ④ ATTENTION [Slides: "Why attention?" → "Combining heads with Wo"]
# ═════════════════════════════════════════════════════════════════════════════
# 💬 "This class is the heart of the workshop. The 7 numbered steps in forward()
# map one-to-one onto the attention slides. Everything else is plumbing."
#
# Teaching tip: walk forward() with a concrete shape, e.g. B=32, T=256, C=256,
# n_head=4, d_k=64 — and write the shapes on the board as you go.
class CausalSelfAttention(nn.Module):
"""Multi-head causal self-attention. One linear projects to Q,K,V together."""
def __init__(self, cfg: GPTConfig):
super().__init__()
# d_k = n_embd / n_head must divide evenly — each head gets a clean slice.
# [Slide: "Multi-head attention" — d_k = n_embd / n_head]
assert cfg.n_embd % cfg.n_head == 0, "n_embd must be divisible by n_head"
self.n_head = cfg.n_head
self.n_embd = cfg.n_embd
self.d_k = cfg.n_embd // cfg.n_head
# 💬 "The slides show three separate matrices Wq, Wk, Wv, each (C × C).
# In code we fuse them into ONE (C × 3C) matrix for efficiency —
# one matmul instead of three. Same math, same parameter count."
# [Slide: "Single-head attention: Q, K, V"]
self.qkv = nn.Linear(cfg.n_embd, 3 * cfg.n_embd)
# Wo from the slides: lets the heads talk to each other after running
# independently. Without it, heads would be siloed.
# [Slide: "Combining heads with Wo"]
self.proj = nn.Linear(cfg.n_embd, cfg.n_embd)
self.dropout = nn.Dropout(dropout)
# 💬 "The causal mask is NOT learned — it's a fixed triangle of 1s.
# Row i has 1s up to column i: 'token i may look at tokens 0..i'."
# [Slide: "Causal mask"] and [Slide: "What gets learned, what stays fixed"]
# register_buffer = "part of the model, moves with .to(device),
# saved in state_dict, but NO gradients" — perfect for a constant.
mask = torch.tril(torch.ones(cfg.block_size, cfg.block_size))
self.register_buffer("mask", mask.view(1, 1, cfg.block_size, cfg.block_size))
def forward(self, x):
B, T, C = x.shape # batch, seq_len, n_embd — write these on the board
# ── 1) Project to Q, K, V ──────────────── [Slide: "Q, K, V"]
# One big matmul gives (B, T, 3C); split() carves it into three (B, T, C).
# 💬 "Query: what am I looking for? Key: what do I offer? Value: what do
# I pass along if matched?"
q, k, v = self.qkv(x).split(self.n_embd, dim=2)
# ── 2) Split into heads ────────── [Slide: "Multi-head attention"]
# (B, T, C) → (B, T, n_head, d_k) → transpose → (B, n_head, T, d_k)
# 💬 "No new computation here — we're just reshaping so each head can run
# the SAME attention math independently on its own d_k-sized slice."
q = q.view(B, T, self.n_head, self.d_k).transpose(1, 2)
k = k.view(B, T, self.n_head, self.d_k).transpose(1, 2)
v = v.view(B, T, self.n_head, self.d_k).transpose(1, 2)
# ── 3) Scaled dot-product scores ──── [Slide: "Attention scores (scaled)"]
# (B, nh, T, d_k) @ (B, nh, d_k, T) → (B, nh, T, T)
# 💬 "A T×T grid per head: how relevant is every token to every other token."
# ⚠️ The 1/√d_k scaling is the line students forget. Without it, dot
# products grow with d_k → softmax saturates → gradients vanish.
scores = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(self.d_k))
# ── 4) Causal mask ──────────────────────── [Slide: "Causal mask"]
# Where the triangle has 0 (future positions), drop in -inf.
# 💬 "-inf BEFORE softmax becomes exactly 0 AFTER softmax — the model
# literally cannot peek at the answer."
# [:T, :T] crops the precomputed block_size mask to the actual seq length.
scores = scores.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf"))
# ── 5) Softmax → attention weights ──── [Slide: "Softmax intuition"]
# Each row becomes a probability distribution: positive, sums to 1,
# behaves like "importance".
attn = F.softmax(scores, dim=-1)
attn = self.dropout(attn) # regularization: randomly drop some attention links
# ── 6) Apply attention to V ────────────── [Slide: "Apply attention"]
# (B, nh, T, T) @ (B, nh, T, d_k) → (B, nh, T, d_k)
# 💬 "Each output row is a weighted BLEND of value vectors from earlier
# positions. THIS is the heart of the transformer."
out = attn @ v
# ── 7) Re-combine heads + Wo ──── [Slide: "Combining heads with Wo"]
# (B, nh, T, d_k) → (B, T, nh, d_k) → (B, T, C): concat of all heads.
# ⚠️ .contiguous() is needed because transpose only changes the view,
# not memory layout — .view() requires contiguous memory.
out = out.transpose(1, 2).contiguous().view(B, T, C)
out = self.proj(out) # Wo: mixes information across heads
return out
# ═════════════════════════════════════════════════════════════════════════════
# ⑤ FFN [Slide: "Feed-Forward Network (FFN)"]
# ═════════════════════════════════════════════════════════════════════════════
# 💬 "Attention mixes information ACROSS tokens; the FFN processes each token
# INDEPENDENTLY — same two layers applied to every position. Expand to 4×
# (room to think), non-linearity, compress back."
class FeedForward(nn.Module):
"""Two-layer MLP: expand to 4x, GELU, compress back."""
def __init__(self, cfg: GPTConfig):
super().__init__()
d_ff = 4 * cfg.n_embd # the classic 4× expansion (slide: d_ff = 4d)
self.fc1 = nn.Linear(cfg.n_embd, d_ff) # W1: expand (C → 4C)
self.fc2 = nn.Linear(d_ff, cfg.n_embd) # W2: compress (4C → C)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# expand → GELU (GPT's choice over ReLU) → compress → dropout
# ❓ Ask: "Why is the non-linearity essential?" → without it, fc2(fc1(x))
# collapses into a single linear layer; depth would buy nothing.
return self.dropout(self.fc2(F.gelu(self.fc1(x))))
# ═════════════════════════════════════════════════════════════════════════════
# ⑥ TRANSFORMER BLOCK [Slide: "One full transformer block"]
# ═════════════════════════════════════════════════════════════════════════════
# 💬 "This is the repeating unit — the slide diagram in 3 lines of code.
# PRE-norm: LayerNorm goes BEFORE each sublayer (GPT-2/modern convention),
# and the residual 'x +' is the highway that lets gradients flow through
# deep stacks."
# [Slide: "Residual + LayerNorm"]
class TransformerBlock(nn.Module):
"""Pre-norm block: LN -> Attn -> +residual -> LN -> FFN -> +residual"""
def __init__(self, cfg: GPTConfig):
super().__init__()
self.ln1 = nn.LayerNorm(cfg.n_embd) # γ, β — learned (2 × n_embd params)
self.attn = CausalSelfAttention(cfg)
self.ln2 = nn.LayerNorm(cfg.n_embd) # second LN, own γ, β
self.ffn = FeedForward(cfg)
def forward(self, x):
# 💬 Read these aloud as: "x plus attention-of-normalized-x" —
# the residual means each sublayer only learns a CORRECTION to x.
x = x + self.attn(self.ln1(x)) # sublayer 1: communicate (across tokens)
x = x + self.ffn(self.ln2(x)) # sublayer 2: compute (per token)
return x
# ═════════════════════════════════════════════════════════════════════════════
# ③ THE FULL GPT [Slide: "Recap: what we just built"]
# ═════════════════════════════════════════════════════════════════════════════
# 💬 Teaching tip: show __init__ + forward() FIRST as the bird's-eye view —
# it mirrors the recap-slide pipeline line by line — then descend into
# attention. People hold details better once they've seen the skeleton.
class GPT(nn.Module):
"""The whole model: embeddings + N blocks + final LN + LM head."""
def __init__(self, cfg: GPTConfig):
super().__init__()
self.cfg = cfg
# Token embedding table: (vocab_size × n_embd), learned lookup.
# [Slide: "Embeddings" — "initialized randomly, updated during training"]
self.tok_emb = nn.Embedding(cfg.vocab_size, cfg.n_embd)
# LEARNED positional encoding (GPT-style), one vector per position.
# [Slide: "Positional encoding" — the 'Learned' flavor, not sinusoidal]
self.pos_emb = nn.Embedding(cfg.block_size, cfg.n_embd)
self.drop = nn.Dropout(dropout)
# The stack: n_layer identical-shaped blocks, each with its OWN weights.
# [Slide: "Stacking layers"]
self.blocks = nn.ModuleList([TransformerBlock(cfg) for _ in range(cfg.n_layer)])
self.ln_f = nn.LayerNorm(cfg.n_embd) # final LN before the head
# LM head: project (B, T, C) back to (B, T, vocab) — a score per token.
# [Slide: "Output logits"]
self.head = nn.Linear(cfg.n_embd, cfg.vocab_size, bias=False)
# 💬 WEIGHT TYING: the output head and the input embedding SHARE one
# matrix (used transposed in the matmul). Saves vocab_size × n_embd
# params and works well in practice — mentioned on the logits slide.
# ⚠️ This is why the parameter count printout is ~16K lower than the
# worked example on the slides (which counts the head separately).
self.head.weight = self.tok_emb.weight
# Initialize all weights small and Gaussian (std 0.02, the GPT-2 recipe).
# ❓ "Why not zeros?" → all-zero weights = all neurons identical = no
# symmetry breaking; nothing distinct to learn.
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0.0, std=0.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Embedding):
nn.init.normal_(m.weight, mean=0.0, std=0.02)
def num_parameters(self) -> int:
# 💬 Compare the printout with the slide's worked example (~3.25M).
# [Slide: "Parameter count: worked example"]
return sum(p.numel() for p in self.parameters() if p.requires_grad)
def forward(self, idx, targets=None):
"""
idx: (B, T) token IDs
targets: (B, T) next-token IDs (for training); None for inference
returns: logits (B, T, vocab_size), loss or None
💬 "ONE forward pass serves both training and inference — same brain,
different loop. targets=None is the only switch."
[Slide: "Training vs. inference"]
"""
B, T = idx.shape
assert T <= self.cfg.block_size, f"sequence length {T} > block_size {self.cfg.block_size}"
# ── The recap-slide pipeline, line by line ──
tok = self.tok_emb(idx) # (B, T, C) token IDs → vectors
pos = self.pos_emb(torch.arange(T, device=idx.device)) # (T, C) position 0..T-1 → vectors
x = self.drop(tok + pos) # (B, T, C) X = E + position
# ⚠️ tok is (B,T,C), pos is (T,C) — broadcasting adds the same position
# vectors to every sequence in the batch. Worth pausing on.
for block in self.blocks: # n_layer blocks, each refines x
x = block(x)
x = self.ln_f(x) # final LayerNorm [Slide: "Stacking layers"]
logits = self.head(x) # (B, T, vocab)
loss = None
if targets is not None:
# ── TRAINING branch ── [Slides: "Cross-entropy loss"]
# 💬 "The model predicts the next token at EVERY position in
# parallel — T predictions per sequence, not 1. That's why
# transformer training is so efficient."
# Flatten (B, T, vocab) → (B·T, vocab) and (B, T) → (B·T,)
# because F.cross_entropy wants (N, classes) and (N,) of true IDs.
# ⚠️ cross_entropy takes raw LOGITS — it applies softmax + -log(p_t)
# internally. Don't softmax twice (a classic live-coding bug).
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)),
targets.view(-1),
)
return logits, loss
# ═════════════════════════════════════════════════════════════════════════
# ⑨ GENERATION [Slide: "Generation: from logits to text"]
# ═════════════════════════════════════════════════════════════════════════
@torch.no_grad() # inference: no gradients, no backprop — weights frozen
def generate(self, idx, num_new_tokens: int, temperature: float = 1.0,
top_k: int | None = None) -> torch.Tensor:
"""Autoregressively generate num_new_tokens tokens.
💬 "The slide's loop: last logits → softmax → sample → append → repeat.
One token at a time. This is how GPT writes a sentence."
"""
self.eval() # switches dropout OFF [Slide: "Training vs. inference"]
for _ in range(num_new_tokens):
# If the running text exceeds block_size, keep only the last
# block_size tokens — the model can't attend beyond its context.
# 💬 "This IS the 'context window' people talk about in big LLMs."
idx_cond = idx if idx.size(1) <= self.cfg.block_size else idx[:, -self.cfg.block_size:]
logits, _ = self(idx_cond) # full forward pass; loss is None here
# Take only the LAST position's logits — the next-token prediction.
# (Training used all T positions; inference uses just one.)
# TEMPERATURE: divide logits before softmax.
# <1.0 sharpens (more confident/repetitive), >1.0 flattens (wilder).
# ⚠️ max(temperature, 1e-8) guards against divide-by-zero at temp=0.
logits = logits[:, -1, :] / max(temperature, 1e-8)
# TOP-K: keep only the k highest-scoring tokens, set the rest to
# -inf (so softmax gives them probability 0). Stops the model from
# ever sampling a wildly unlikely character.
if top_k is not None and top_k > 0:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = float("-inf") # v[:, [-1]] = k-th best score
probs = F.softmax(logits, dim=-1) # scores → probabilities
next_id = torch.multinomial(probs, num_samples=1) # SAMPLE (not argmax) (B, 1)
# ❓ Ask: "What changes if we use argmax instead?" → deterministic,
# and typically loops/repeats. Sampling is where variety comes from.
idx = torch.cat([idx, next_id], dim=1) # append & loop
return idx
# ═════════════════════════════════════════════════════════════════════════════
# ⑦ DATA: making (input, target) pairs
# ═════════════════════════════════════════════════════════════════════════════
# 💬 "Where do the 'answer keys' come from? The text itself. The target is the
# input shifted one character to the right — free labels, no human needed.
# This is what 'self-supervised' means."
#
# data: [T, h, e, _, c, a, t]
# x = [T, h, e, _, c, a]
# y = [h, e, _, c, a, t] ← y[i] is the 'next token' after x[i]
def get_batch(data: torch.Tensor, block_size: int, batch_size: int,
device: torch.device) -> tuple[torch.Tensor, torch.Tensor]:
"""Sample batch_size random windows of length block_size from data."""
# Random start indices; -1 leaves room for the shifted target.
ix = torch.randint(0, len(data) - block_size - 1, (batch_size,))
x = torch.stack([data[i:i + block_size] for i in ix]) # inputs
y = torch.stack([data[i + 1:i + 1 + block_size] for i in ix]) # same, shifted +1
return x.to(device), y.to(device)
# ⚠️ Random windows ≠ epochs. We sample with replacement, so "one epoch"
# isn't well-defined here — we just count steps. Fine at this scale.
# ═════════════════════════════════════════════════════════════════════════════
# ⑧ TRAIN COMMAND [Slides: "Why we minimize it" → "Training"]
# ═════════════════════════════════════════════════════════════════════════════
# 💬 The training slide's loop, in code:
# batch → forward → loss → backward (gradients) → optimizer step → repeat.
# Map each line of the loop below onto that diagram as you scroll.
def train(args):
device = torch.device("cpu") # CPU-only, by design for the workshop
torch.manual_seed(1337) # fixed seed → everyone in the room gets the
# same loss curve. All of us get same model.
# ── 1) Load data: just a plain text file ──
if not os.path.exists(args.data):
sys.exit(f"Data file not found: {args.data}")
with open(args.data, "r", encoding="utf-8") as f:
text = f.read()
print(f"Loaded {len(text):,} characters from {args.data}")
# ── 2) Build tokenizer FROM the data ──
# 💬 "vocab_size isn't chosen by us — it falls out of the data. For tiny
# Shakespeare it's 65: letters, digits, punctuation, newline."
tokenizer = CharTokenizer.from_text(text)
print(f"Vocab size: {tokenizer.vocab_size}")
# ── 3) Encode the whole corpus ONCE; split 90/10 train/val ──
# ❓ Ask: "Why hold out a validation set?" → train loss can fall from
# memorization; val loss tells us if the model GENERALIZES. Watch the
# gap between the two columns in the printout.
data = torch.tensor(tokenizer.encode(text), dtype=torch.long)
n_train = int(0.9 * len(data))
train_data = data[:n_train]
val_data = data[n_train:]
print(f"Train tokens: {len(train_data):,} Val tokens: {len(val_data):,}")
# ── 4) Build the model from the 5 numbers ──
cfg = GPTConfig(vocab_size=tokenizer.vocab_size)
model = GPT(cfg).to(device)
# 💬 Pause on this printout and reconcile it with the parameter-count
# slides (~3.25M). Slight difference = weight tying (head not double-counted).
print(f"Model parameters: {model.num_parameters():,}")
# ── 5) Optimizer: AdamW ── [Slide: "From gradients to weight updates"]
# 💬 "AdamW = the slide's `w -= lr × gradient`, but with per-weight adaptive
# step sizes from running averages of past gradients. Used by GPT-2/3,
# LLaMA — and by us."
# weight_decay gently pulls weights toward 0 — regularization.
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4, weight_decay=0.1)
# LR schedule: linear WARMUP (first 100 steps), then COSINE DECAY to min_lr.
# 💬 "Warmup: start gentle while weights are random garbage. Cosine: take
# smaller steps as we converge — like slowing down when parallel parking."
# ❓ "What's lr at step 0? At step `warmup`? At step max_steps?" → trace it.
def lr_at(step: int, max_steps: int, base_lr: float = 3e-4,
warmup: int = 100, min_lr: float = 3e-5) -> float:
if step < warmup:
return base_lr * (step + 1) / warmup # ramp 0 → base_lr
progress = (step - warmup) / max(1, max_steps - warmup)
progress = min(1.0, progress)
return min_lr + 0.5 * (base_lr - min_lr) * (1 + math.cos(math.pi * progress))
# ── 6) Training loop ──
# Fixed sample prompts so the audience can WATCH the same prompt improve
# from noise → words → Shakespeare-ish as training progresses.
sample_prompts = ["To be, or not ", "For I am falser than vows made in"]
log_path = f"{output_path}/loss_log.csv" # for graphing the loss curve later
log_file = open(log_path, "w", newline="")
log_writer = csv.writer(log_file)
log_writer.writerow(["step", "train_loss", "val_loss", "lr"])
# Derived intervals: 10 evals, 5 sample dumps, 4 checkpoints per run,
# regardless of --max-steps.
eval_every = max(1, args.max_steps // 10)
sample_every = max(1, args.max_steps // 5)
ckpt_every = max(1, args.max_steps // 4)
t0 = time.time()
model.train() # dropout ON
for step in range(args.max_steps):
# Set this step's learning rate (PyTorch optimizers read it from
# param_groups; we overwrite it each step with our schedule).
lr = lr_at(step, args.max_steps)
for g in optimizer.param_groups:
g["lr"] = lr
# ══ THE four lines that ARE training ══ [Slide: "Training"]
xb, yb = get_batch(train_data, cfg.block_size, batch_size, device)
_, loss = model(xb, yb) # 1. forward → loss (one number)
optimizer.zero_grad(set_to_none=True) # 2. clear last step's gradients
# ⚠️ Forgetting zero_grad is THE classic bug: PyTorch ACCUMULATES
# gradients by default, so they'd pile up across steps.
loss.backward() # 3. backprop: chain rule, automatic
# [Slide: "How backprop computes gradients"]
optimizer.step() # 4. nudge EVERY weight a tiny bit
# ── Periodic eval + logging ──
if step % eval_every == 0 or step == args.max_steps - 1:
model.eval() # dropout OFF for a fair measurement
with torch.no_grad(): # no gradient bookkeeping needed
xv, yv = get_batch(val_data, cfg.block_size, batch_size, device)
_, val_loss = model(xv, yv)
elapsed = time.time() - t0
# 💬 Narrate the first line: loss ≈ 4.17 ≈ ln(65) — the loss of a
# UNIFORM guess over 65 chars ("Model B" on the cross-entropy
# slide). Watching it fall below that = the model is learning.
print(f"step {step:5d} | lr {lr:.2e} | train {loss.item():.4f} | "
f"val {val_loss.item():.4f} | {elapsed:.1f}s")
log_writer.writerow([step, loss.item(), val_loss.item(), lr])
log_file.flush() # so the CSV is graphable mid-run
model.train() # back to training mode
# ── Periodic samples: the workshop's "wow" moment ──
# 💬 Early samples are gibberish; mid-run grows words and line breaks;
# late samples look like a drunk Shakespeare. Same prompts each time
# makes the progress visible.
if step % sample_every == 0 and step > 0:
model.eval()
for p in sample_prompts:
ids = torch.tensor([tokenizer.encode(p)], dtype=torch.long, device=device)
out = model.generate(ids, num_new_tokens=80, temperature=0.8, top_k=20)
generated = tokenizer.decode(out[0].tolist())
print(f" sample: {generated!r}")
model.train()
# ── Periodic checkpoints (resume / compare across training stages) ──
if step > 0 and step % ckpt_every == 0:
save_checkpoint(model, tokenizer, cfg, f"{output_path}/ckpt_step_{step}.pt")
# Final checkpoint — this is what the generate command loads.
save_checkpoint(model, tokenizer, cfg, f"{output_path}/final_checkpoint.pt")
log_file.close()
print(f"Done. Wrote final_checkpoint.pt and {log_path}.")
def save_checkpoint(model: GPT, tokenizer: CharTokenizer, cfg: GPTConfig, path: str):
# 💬 "A checkpoint must contain everything needed to rebuild the model:
# 1. the weights, 2. the 5 numbers (shape), 3. the vocab (so token IDs
# decode to the same characters). Forget the vocab → garbage output."
torch.save({
"model_state": model.state_dict(), # every learned tensor, by name
"config": asdict(cfg), # the 5 numbers
"vocab": tokenizer.vocab, # the character list
}, path)
print(f" saved {path}")
# ═════════════════════════════════════════════════════════════════════════════
# GENERATE COMMAND — checkpoint in, text out
# ═════════════════════════════════════════════════════════════════════════════
# 💬 "Inference = rebuild the exact same model, load frozen weights, loop
# generate(). No loss, no gradients, no optimizer — compare the two columns
# of the 'Training vs. inference' slide."
def generate(args):
device = torch.device("cpu")
if args.seed is not None:
torch.manual_seed(args.seed) # same seed + same prompt → same output
# 💬 Good demo: run twice with --seed 42 (identical), then without (varies).
if not os.path.exists(args.checkpoint):
sys.exit(f"Checkpoint not found: {args.checkpoint}")
# ⚠️ weights_only=False because our checkpoint also carries config + vocab
# (not just tensors). Fine for our OWN files; for untrusted downloads
# you'd want weights_only=True (it restricts unpickling).
ckpt = torch.load(args.checkpoint, map_location=device, weights_only=False)
# Rebuild the exact architecture and tokenizer the checkpoint was saved with:
cfg = GPTConfig(**ckpt["config"]) # the 5 numbers → same shapes
tokenizer = CharTokenizer(ckpt["vocab"]) # same vocab → same ID↔char mapping
model = GPT(cfg).to(device)
model.load_state_dict(ckpt["model_state"]) # pour the learned weights back in
model.eval() # inference mode: dropout off
# prompt → IDs → generate → IDs → text. The full round trip from slide 1.
ids = torch.tensor([tokenizer.encode(args.prompt)], dtype=torch.long, device=device)
out = model.generate(
ids,
num_new_tokens=args.num_new_tokens,
temperature=args.temperature, # ❓ live demo: try 0.2 vs 1.5 and compare
top_k=args.top_k,
)
print(tokenizer.decode(out[0].tolist()))
# ═════════════════════════════════════════════════════════════════════════════
# CLI — two subcommands, as promised on the "Hands-on: the plan" slide
# ═════════════════════════════════════════════════════════════════════════════
def main():
parser = argparse.ArgumentParser(description="Tiny GPT: train and generate")
sub = parser.add_subparsers(dest="cmd", required=True)
# train: only data + steps are CLI args; architecture lives in GPTConfig.
p_train = sub.add_parser("train", help="Train the model from a text file")
p_train.add_argument("--data", required=True, help="path to UTF-8 text file")
p_train.add_argument("--max-steps", type=int, default=2000)
p_train.set_defaults(func=train)
# generate: checkpoint + prompt + the sampling knobs from the slides.
p_gen = sub.add_parser("generate", help="Generate text from a checkpoint")
p_gen.add_argument("--checkpoint", required=True)
p_gen.add_argument("--prompt", required=True)
p_gen.add_argument("--num-new-tokens", type=int, default=500)
p_gen.add_argument("--temperature", type=float, default=0.8)
p_gen.add_argument("--top-k", type=int, default=40)
p_gen.add_argument("--seed", type=int, default=None)
p_gen.set_defaults(func=generate)
args = parser.parse_args()
args.func(args) # dispatch to train() or generate()
if __name__ == "__main__":
main()