Getting started with RDF using Blazegraph
This started as a simple exercise of querying WikiData database using their SPQRQL query service. That lead me to studying about RDF and Triplets. I found it very interesting. I spent hours on it. So I thought I might as well write about it here, so I can refer it later. So everything here is how I went about learning it.
Table of Contents
Semantic Web, Triple and Triplestore
Web was meant to be for humans. But at some point it also became machine readable. Semantic web is an extension to Web to make it more machine readable. Technologies like RDF (Resource Description Framework) and OWL (Web Ontology Language) are used to express the semantic web. RDF is an assertional language, it provide a way to express proposition (a statement or expression that is true or false). using predefined vocabularies.
RDFS or RDF Schema provides all the vocabulary required to model the RDF data. It’s an extension to RDF Vocabulary.
In semantic web/RDF, the atomic level unit is called a semantic triple or triple. It’s in the form of a statement and contains three items of data. Its in the form of subject-predicate-object.
Examples:
- Thej’s age is 35
- Thej Knows Raj
Where Thej is the subject, age is is predicate and 35 is Object. Each of them can be complex entities themselves. This looks very similar to Entity – Attribute – Value design.
Since this structure is very different from how the data stored in RDBMS (Tables and Rows) looks. It needs a particular kind of database to store it. Its usually called a triplestore or RDF store. Its usually purpose build to store RDF data. One such is Blazegraph.
There are also serialization formats to actually contain the data. Most popular ones are RDF/XML, JSON-LD, Turtle etc You could use this formats to store the data or use it export from one system to importing into another system etc.
It is based on the idea of making statements about resources (in particular web resources) in expressions of the form subject–predicate–object, known as triples. The subject denotes the resource, and the predicate denotes traits or aspects of the resource, and expresses a relationship between the subject and the object.
Wikipedia
Blazegraph
Blazegraph is an open source graph database (aka Triplestore) that I can install locally and import triples (data) into it. Then like any database one can query it for data. The query language used is called SPARQL.
Blazegraph™ DB is a ultra high-performance graph database supporting Blueprints and RDF/SPARQL APIs. It supports up to 50 Billion edges on a single machine. It is in production use for Fortune 500 customers such as EMC, Autodesk, and many others. It is supporting key Precision Medicine applications and has wide-spread usage for life science applications. It is used extensively to support Cyber anaytics in commercial and government applications. It powers the Wikimedia Foundation’s Wikidata Query Service.
Blazegraph
Download and install the database.
Blazegraph needs Java (Java 9+) runtime. It runs fine on OpenJDK. So install the JDK from AdoptOpenJDK and install it. Once you have java running. Download the Blazegraph executable JAR – blazegraph.jar , from their Github release page.
Once you download you can start it using the command
java -server -Xmx4g -jar blazegraph.jar
Once it starts you can access te blazegraph workbench at http://localhost:9999/blazegraph/. Data is stored in blazegraph.jnl in the same folder.
Import some data
There are couple of file formats that can be used to store RDF data. They all are text files. The popular ones are Turtle, N-Triples, JSON-LD and RDF/XML.
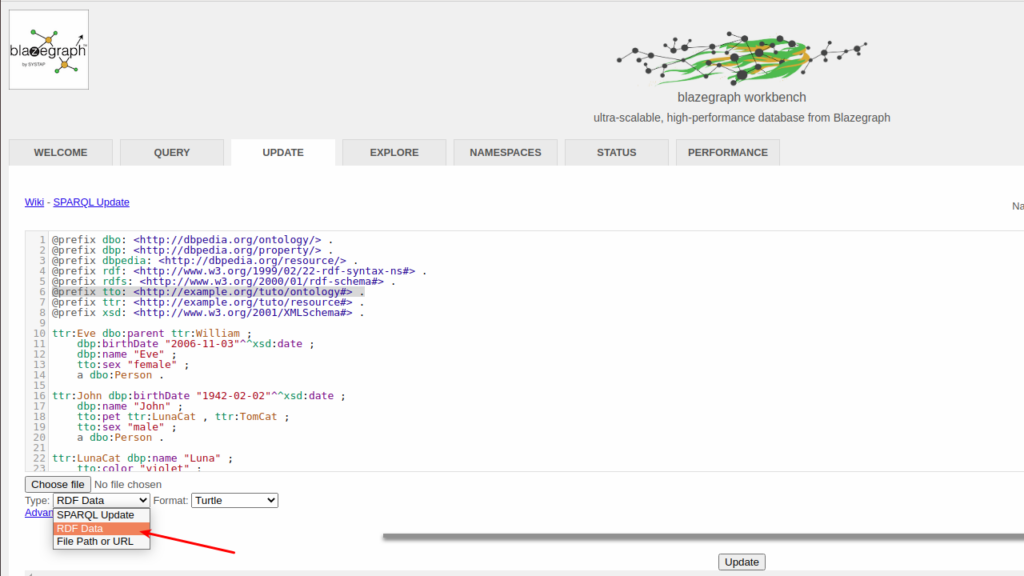
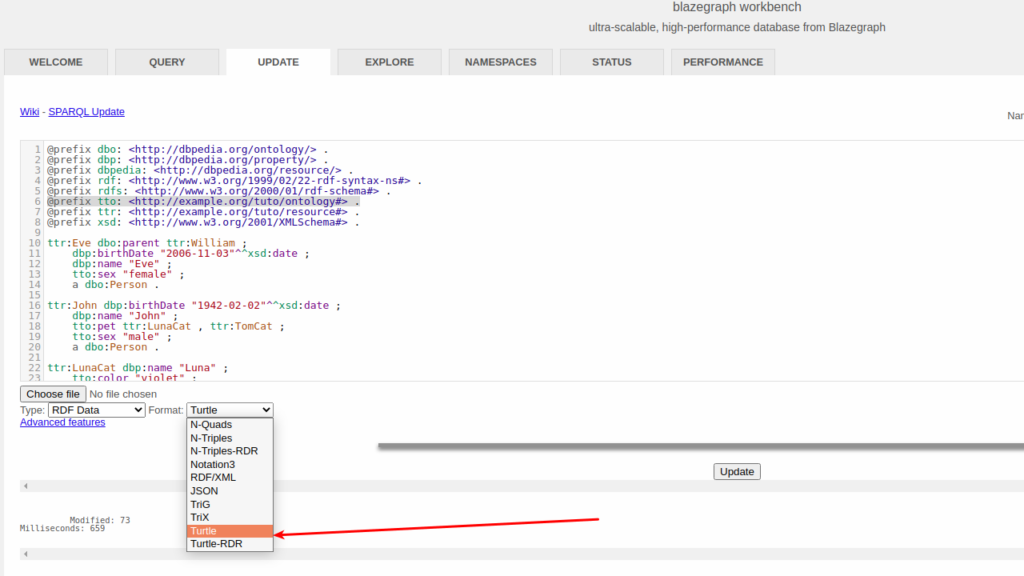
Let’s take a simple dateset in Turtle format. Its an example from the book Learning SPARQL. It has seven statements.
# filename: ex002.ttl
@prefix ab: <http://learningsparql.com/ns/addressbook#> .
ab:richard ab:homeTel "(229) 276-5135" .
ab:richard ab:email "richard49@hotmail.com" .
ab:cindy ab:homeTel "(245) 646-5488" .
ab:cindy ab:email "cindym@gmail.com" .
ab:craig ab:homeTel "(194) 966-1505" .
ab:craig ab:email "craigellis@yahoo.com" .
ab:craig ab:email "c.ellis@usairwaysgroup.com" .
Importing that is very straight forward. Choose the Type and Format. Paste the data in the text area. Click on Update button. It shows how many statements are modified. In this case you can see, we have uploaded.modified 7 statements.
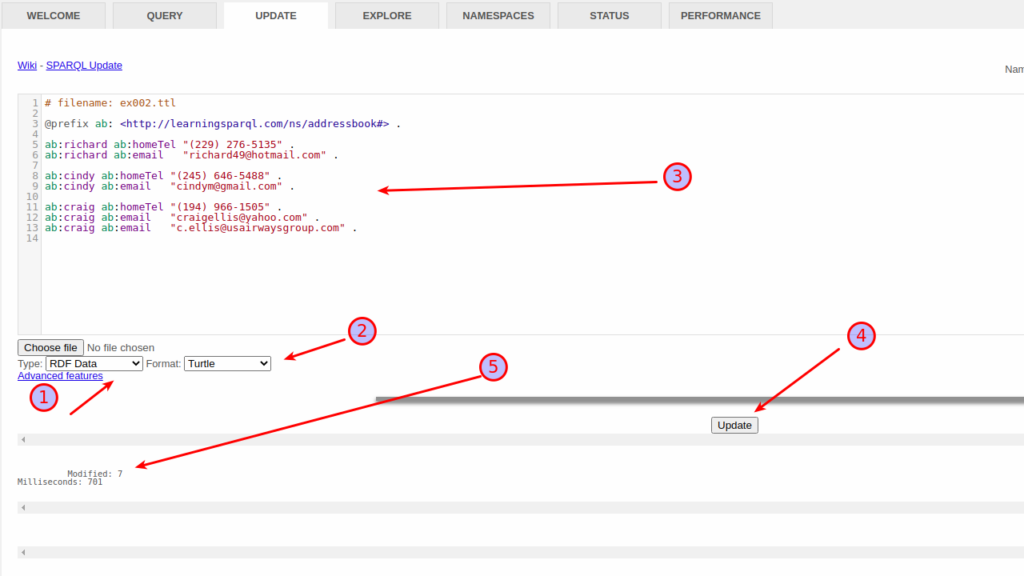
Then paste the data in the text box above like its show in the picture and then click import.
Next – SPARQL
SPARQL is the query language used to query RDF, similar to how SQL is used to query RDBMS. There are some common things but lots and lots of differences. In the next post we explore SPARQL by querying our dataset which we just inserted and then we will also query WikiData.











1 Response
[…] blog post is in continuation to my other blog posts about Learning about Semantic Web and Triple, Trying […]