Readlists
I love readlists. After it closed down, I used the pinboard’s tag as a way to share it. For a long time, I wanted to own the process and data. Now I do.
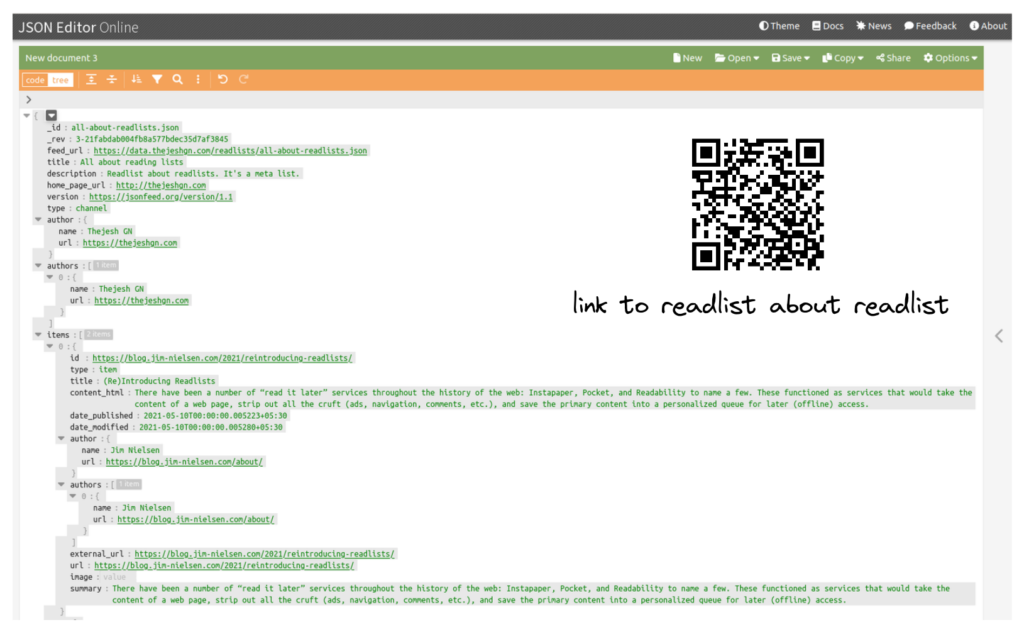
My readlists are primarily around a subject that I want to share or use for my reading. It’s different from my ReadItLater, which is for my private reading only. Hence a different flow. I found Jim Nielsen readlists. He has his own format, which resembles Mercury scraper’s JSON format. But I wanted a standard that makes it easy for me to share and for others to use their favorite client to read. So I went for a JSONFeed format. So every list is a channel, and every article is an item. Most times, I get bare-bone articles, as I am not 100% sure about embedding the entire content in a public feed.
Each channel is stored as a document in CouchDB and served as it is. I have a CLI tool in development that I use against a CouchDB database to maintain the lists. It uses Trafilatura API to pull the article details and then formats them into FeedJSON format before adding them to CouchDB. I will release it once it reaches v0.1.
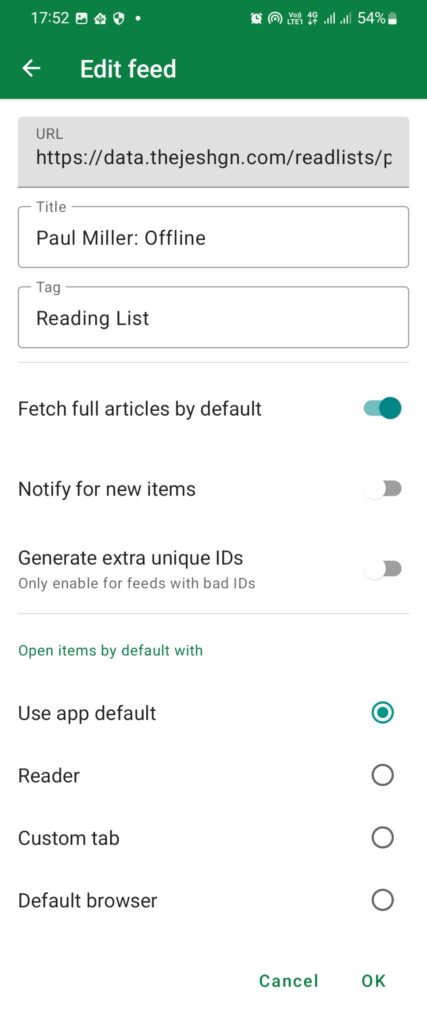
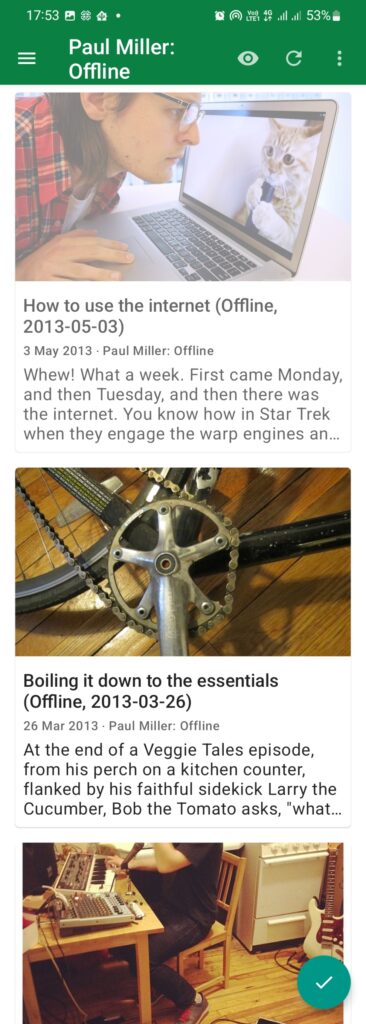
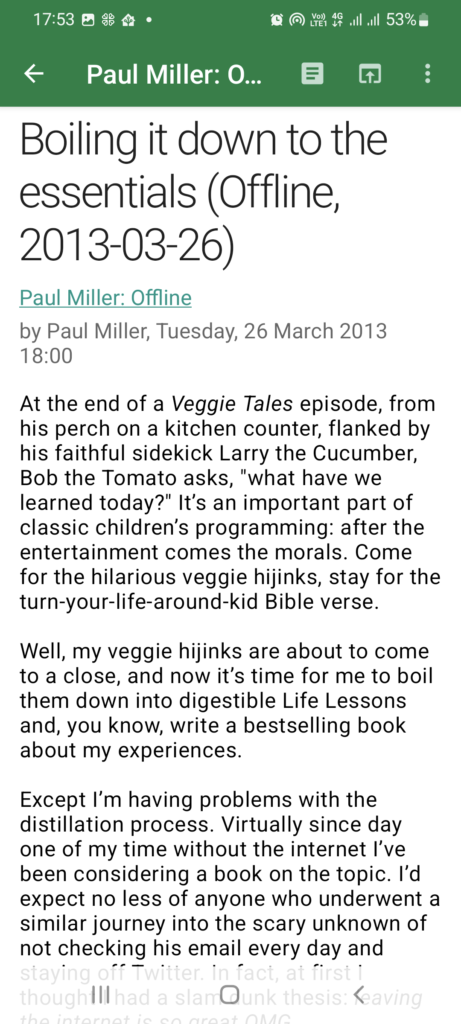
Here is an example feed Paul Miller: Offline this is a copy of Jim Nielsen’s Readlist but in JSONFeed format and without full content. I could add content if required, especially if I doubt the content will vanish. My feed reader will pull the full content based on the setting. It works on most sites, so my offline reading is not a problem.
I also have a meta readlist.











