Indie ReadLater using Mercury Web Scraper, CouchdDB and JSONFeed
You already know I have a pipeline for generating the JSONFeeds. We store the items in CouchDB. We generate feed by pulling items out of CouchDB using a simple server-less script on the output side. You can use any FeedReader app like Feeder to read.
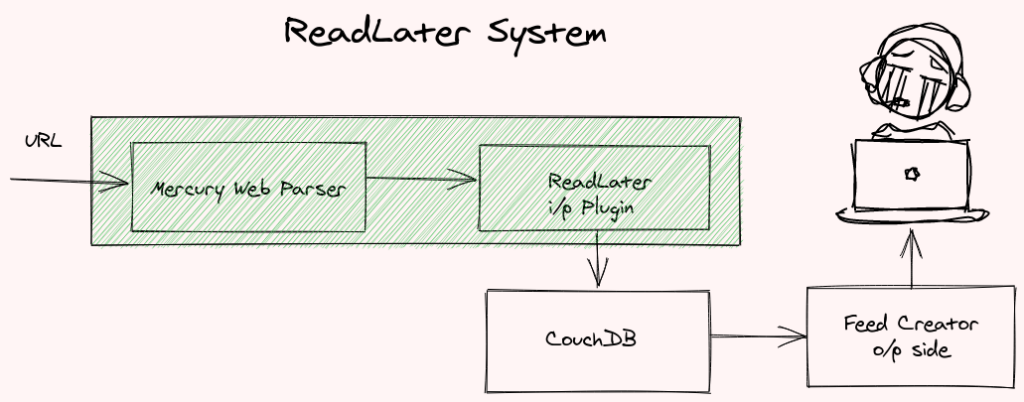
ReadLater is an addition on the input side of the pipeline. In this case, we use Mercury Web Parser to scrape and parse the URL. Then we massage the JSON data produced by Parser into a JSONFeed item. This item is then added to the CouchDB using a simple web post.
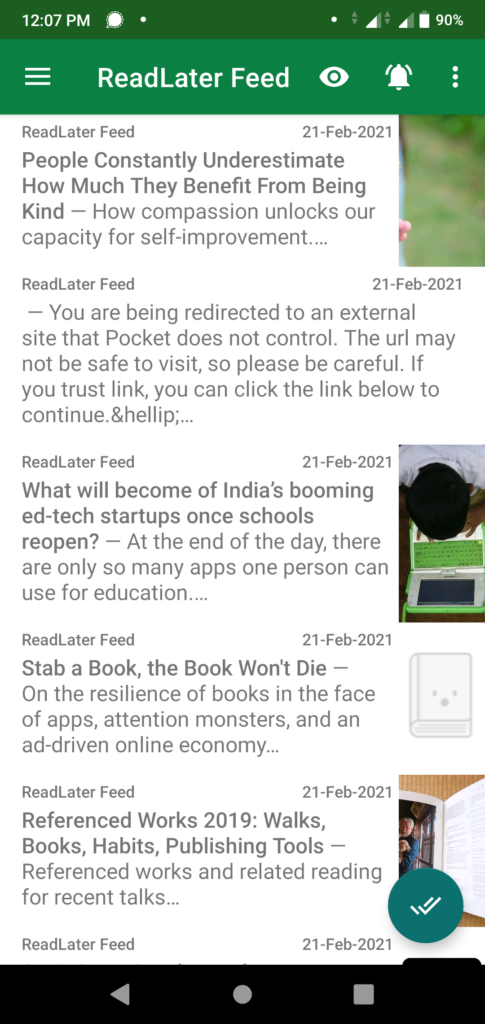
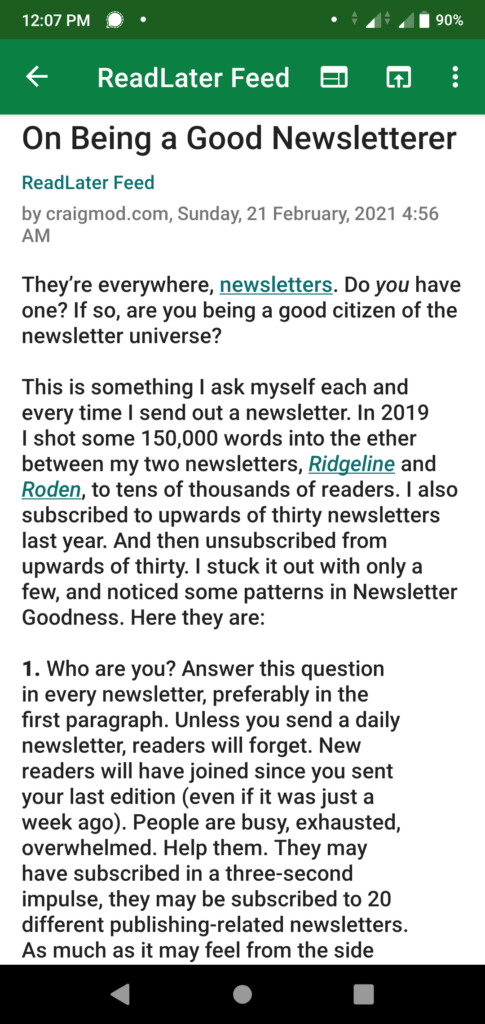
Below is the simple input plugin which takes a URL as input. Passes it to mercury-parser to scrape the web and get article details. Then converts that into a feed item and posts it to my CouchDB river database.
import os
import sys
import json
import datetime
import argparse
import pytz
import requests
from slugify import slugify
river = os.environ["RIVER_URL"]
channel = "readlater"
device = "01"
def get_id(channel, device):
tz = pytz.timezone("Asia/Kolkata")
now = datetime.datetime.now(tz).isoformat()
_id = "{now}_{channel}_{device}".format(
now=slugify(now), channel=channel, device=device
)
return _id
def get_datetime():
tz = pytz.timezone("Asia/Kolkata")
now = datetime.datetime.now(tz).isoformat()
return str(now)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--url", help="Give me a url")
args = parser.parse_args()
url = args.url
stream = os.popen('mercury-parser {url}'.format(url=url))
output = stream.read()
data = json.loads(output)
d = {}
_id = get_id(channel, device)
d["_id"] = _id
d["id"] = _id
d["content_html"] = data["content"]
d["channel"] = channel
d["title"] = data["title"]
d["date_published"] = data["date_published"]
d["date_modified"] = get_datetime()
if "author" in data and data["author"]:
d["author"] = {"name": data["author"]}
else:
d["author"] = {"name": data["domain"]}
d["type"] = "item"
d["external_url"] = url
d["url"] = url
d["image"] = data["lead_image_url"]
d["summary"] = data["excerpt"]
print(d)
r = requests.post(river, json=d)
This system is becoming more and more central to my daily workflow. Its probably time to clean up the code, make it into a package that can be installed easily. I have a code name for it - Hoysala.








1 Response